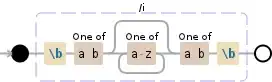
The following perl program has a regex written to serve my purpose. But, this captures results present within a string too. How can I only get strings separated by spaces/newlines/tabs?
The test data I used is present below: http://sainikhil.me/stackoverflow/dictionaryWords.txt
use strict;
use warnings;
sub print_a_b {
my $file = shift;
$pattern = qr/(a|b|A|B)\S*(a|b|A|B)/;
open my $fp, $file;
my $cnt = 0;
while(my $line = <$fp>) {
if($line =~ $pattern) {
print $line;
$cnt = $cnt+1;
}
}
print $cnt;
}
print_a_b @ARGV;