I have a pre-binned frequency table for a rather large dataset. That is, a single column vector of bins and a single column vector of counts associated with those bins. I'd like R to plot a histogram of this data by doing further binning and summing the existing counts. For example, if in the pre-binned data I have something like [(0.01, 5000), (0.02, 231), (0.03, 948)], where the first number is the bin and the second is the count, and I choose 0.04 as the new bin width, I'd expect to get [(0.04, 6179)]. What's the fastest and or easiest way to do this in R?
Asked
Active
Viewed 4,131 times
2 Answers
6
Looks like ggplot2 has the answer.
library(ggplot2)
qplot(bin, data=cbind(bins,counts), weight=counts, geom="histogram")
Jacob
- 161
- 1
- 5
-
you're fast ;) I was just looking up how I did this in the past. I saw two ways I had hacked around this 1) ggplot2 and 2) sampling from the binned data and then rebinning. I much preferred ggplot2 but the rebinning was a hack I cooked up prior to discovering ggplot could do this. – JD Long Sep 24 '10 at 17:32
-
What is the 'bin' object? – fahmy Aug 21 '18 at 06:01
1
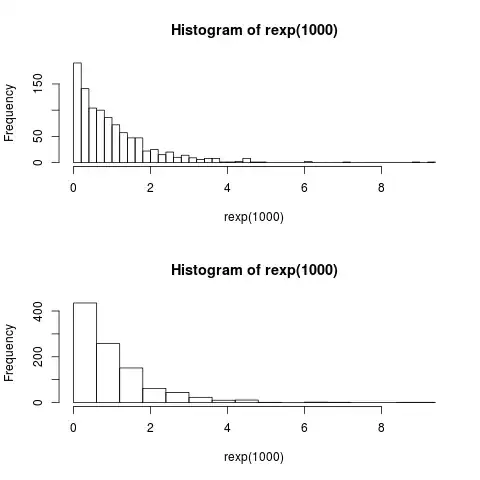
The new HistogramTools package on CRAN has a number of useful functions for doing exactly this. In your example, if you want to merge three adjacent buckets together at each point in the histogram to produce a new histogram with 1/3rd as many buckets, you could use the MergeBuckets function.
install.packages("HistogramTools")
library(HistogramTools)
h <- hist(rexp(1000), breaks=60)
plot(MergeBuckets(h, adj.buckets=3))
Alternatively, you can also specify a list of the new breakpoints you want explicitly, rather than telling MergeBuckets() to always merge the same number of adjacent buckets.
MurrayStokely
- 345
- 2
- 6