Click here for the answer. Turing Machine
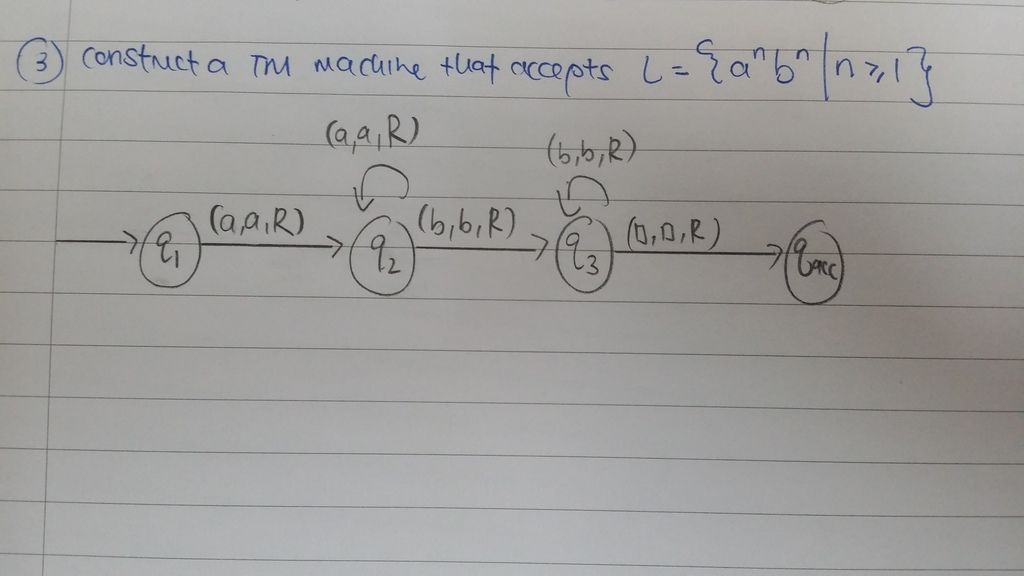{kind=link}
The question is to construct a Turing Machine which accepts the regular expression,
L = {a^n b^n | n>= 1}.
I am not sure if my answer is correct or wrong. Thank you in advance for your reply.
Click here for the answer. Turing Machine
The question is to construct a Turing Machine which accepts the regular expression,
L = {a^n b^n | n>= 1}.
I am not sure if my answer is correct or wrong. Thank you in advance for your reply.
You cannot "accept the regular expression", only the language it describes. And what you provide is not a regular expression, but a set description. In fact, the language is not regular and therefore cannot be described by standard regular expressions.
The machine from your answer accepts the language described by the regular expression a^+ b^+.
A TM could mark the first a (e.g. by converting it to A) then delete the first b. And for each n one loop. If you and up with a string only of A, then accept.
As stated before, language L = {a^nb^n; n >= 1} cannot be described by regular expressions, it doesn't belong into the category of regular grammars. This language in particular is an example of context-free grammar, and thus it can be described by context-free grammar and recognized by pushdown automaton (an automaton with LIFO memory, a stack).
Grammar for this language would look something like this:
G = (V, S, R, P)
Where:
V = { S }S = { a, b }R = { S -> aSb, S -> ab }P = SA pushdown automata recognizing this language would be more complex, as it is a 7-tuple M = (Q, S, G, D, q0, Z, F)
For our case, it would be:
Q = { q0, q1, qF }S = { a, b }G = { z0, X }(current state, input character, top of stack) -> (output state, top of stack) (meaning you can move to a different state and rewrite top of stack (erase it, rewrite it or let it be)
(q0, a, z0) -> (q0, Xz0) - reading the first a(q0, a, X) -> (q0, XX) - reading consecutive a's(q0, b, X) -> (q1, e) - reading first b(q1, b, X) -> (q1, e) - reading consecutive b's(q1, e, z0) -> (qF, e) - reading last bq0 = q0Z = z0F = { qF }The language L = {a^n b^n | n≥1} represents a kind of language where we use only 2 character, i.e., a, b. In the beginning language has some number of a’s followed by equal number of b’s . Any such string which falls in this category will be accepted by this language. The beginning and end of string is marked by $ sign.
Step-1: Replace a by X and move right, Go to state Q1. Step-2: Replace a by a and move right, Remain on same state Replace Y by Y and move right, Remain on same state Replace b by Y and move right, go to state Q2. Step-3: Replace b by b and move left, Remain on same state Replace a by a and move left, Remain on same state Replace Y by Y and move left, Remain on same state Replace X by X and move right, go to state Q0. Step-5: If symbol is Y replace it by Y and move right and Go to state Q4 Else go to step 1 Step-6: Replace Y by Y and move right, Remain on same state If symbol is $ replace it by $ and move left, STRING IS ACCEPTED, GO TO FINAL STATE Q4