This may be a basic question, but I've been searching through many lists to find what I am looking for. Basically, let me describe the data set. I have a set of data from a ticketing system that represents resolved tickets. I'm looking at resolve time of tickets over time to see if my resolution time is going up, going down or leveling off. There are many tickets each day (somewhere around 200 or so). I pull all the data each day and calculate the time in days it took for the ticket to be resolved. I am doing this with R, so I end up with a data frame that looks like:
1/1/2015 INC00001 1.23
1/1/2015 INC00002 .089
and so forth (many tickets each day with a resolution time for each). What I am trying to do is determine some sort of running average for this. What I'd really like is a line plot over time that shows the trend. I've played around with moving averages and such, but my chart is still very choppy. I'm sure there is something built into R that gives a moving / running / cumulative average over time, but I'm still unable to find exactly what I am looking for.
The chart I'd like to see, would resemble something like this:
[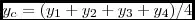
But smoother, sort of like a stock ticker so I kind of know what the overall average is leading up to the current day. Can any one point me in a direction of what this would be called and how one would go about doing this in R? Thanks so much!!
{kind=link}
{kind=link}