I'm using an example extracted from the book "Mastering Machine Learning with scikit learn".
It uses a decision tree to predict whether each of the images on a web page is an advertisement or article content. Images that are classified as being advertisements could then be hidden using Cascading Style Sheets. The data is publicly available from the Internet Advertisements Data Set: http://archive.ics.uci.edu/ml/datasets/Internet+Advertisements, which contains data for 3,279 images.
The following is the complete code for completing the classification task:
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.cross_validation import train_test_split
from sklearn.metrics import classification_report
from sklearn.pipeline import Pipeline
from sklearn.grid_search import GridSearchCV
import sys,random
def main(argv):
df = pd.read_csv('ad-dataset/ad.data', header=None)
explanatory_variable_columns = set(df.columns.values)
response_variable_column = df[len(df.columns.values)-1]
explanatory_variable_columns.remove(len(df.columns.values)-1)
y = [1 if e == 'ad.' else 0 for e in response_variable_column]
X = df[list(explanatory_variable_columns)]
X.replace(to_replace=' *\?', value=-1, regex=True, inplace=True)
X_train, X_test, y_train, y_test = train_test_split(X, y,random_state=100000)
pipeline = Pipeline([('clf',DecisionTreeClassifier(criterion='entropy',random_state=20000))])
parameters = {
'clf__max_depth': (150, 155, 160),
'clf__min_samples_split': (1, 2, 3),
'clf__min_samples_leaf': (1, 2, 3)
}
grid_search = GridSearchCV(pipeline, parameters, n_jobs=-1,verbose=1, scoring='f1')
grid_search.fit(X_train, y_train)
print 'Best score: %0.3f' % grid_search.best_score_
print 'Best parameters set:'
best_parameters = grid_search.best_estimator_.get_params()
for param_name in sorted(parameters.keys()):
print '\t%s: %r' % (param_name, best_parameters[param_name])
predictions = grid_search.predict(X_test)
print classification_report(y_test, predictions)
if __name__ == '__main__':
main(sys.argv[1:])
The RESULTS of using scoring='f1' in GridSearchCV as in the example is:
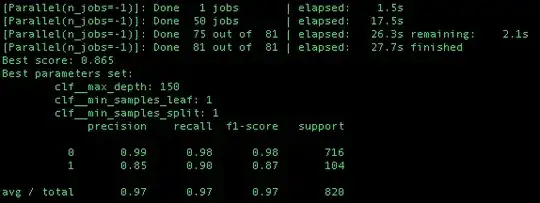
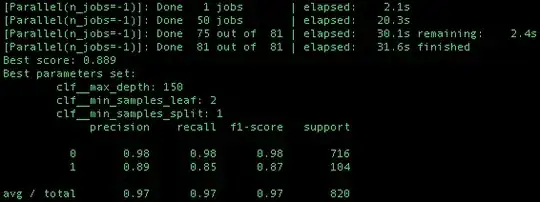
The RESULTS of using scoring=None (by default Accuracy measure) is the same as using F1 score:
If I'm not wrong optimizing the parameter search by different scoring functions should yield different results. The following case shows that different results are obtained when scoring='precision' is used.
The RESULTS of using scoring='precision' is DIFFERENT than the other two cases. The same would be true for 'recall', etc:
WHY 'F1' AND None, BY DEFAULT ACCURACY, GIVE THE SAME RESULT??
EDITED
I agree with both answers by Fabian & Sebastian. The problem should be the small param_grid. But I just wanted to clarify that the problem surged when I was working with a totally different (not the one in the example here) highly imbalance dataset 100:1 (which should affect the accuracy) and using Logistic Regression. In this case also 'F1' and accuracy gave the same result.
The param_grid that I used, in this case, was the following:
parameters = {"penalty": ("l1", "l2"),
"C": (0.001, 0.01, 0.1, 1, 10, 100),
"solver": ("newton-cg", "lbfgs", "liblinear"),
"class_weight":[{0:4}],
}
I guess that the parameter selection is also too small.