Let's say I want to compose an email header with UTF-8, quoted-printable encoded subject, which is "test — UNIX-утилита для проверки типа файла и сравнения значений". I can confirm the bytes of the characters using:
$ echo "UNIX-утилита ..." | perl utfinfo.pl
Got 16 uchars
Char: 'U' u: 85 [0x0055] b: 85 [0x55] n: LATIN CAPITAL LETTER U [Basic Latin]
Char: 'N' u: 78 [0x004E] b: 78 [0x4E] n: LATIN CAPITAL LETTER N [Basic Latin]
Char: 'I' u: 73 [0x0049] b: 73 [0x49] n: LATIN CAPITAL LETTER I [Basic Latin]
Char: 'X' u: 88 [0x0058] b: 88 [0x58] n: LATIN CAPITAL LETTER X [Basic Latin]
Char: '-' u: 45 [0x002D] b: 45 [0x2D] n: HYPHEN-MINUS [Basic Latin]
Char: 'у' u: 1091 [0x0443] b: 209,131 [0xD1,0x83] n: CYRILLIC SMALL LETTER U [Cyrillic]
Char: 'т' u: 1090 [0x0442] b: 209,130 [0xD1,0x82] n: CYRILLIC SMALL LETTER TE [Cyrillic]
Char: 'и' u: 1080 [0x0438] b: 208,184 [0xD0,0xB8] n: CYRILLIC SMALL LETTER I [Cyrillic]
...
So, I'm trying to get the UTF-8, quoted printable representation of this. For instance, using Python's quopri:
$ python -c 'import quopri; a="test — UNIX-утилита для проверки типа файла и сравнения значений"; print(quopri.encodestring(a));'
test =E2=80=94 UNIX-=D1=83=D1=82=D0=B8=D0=BB=D0=B8=D1=82=D0=B0 =D0=B4=D0=BB=
=D1=8F =D0=BF=D1=80=D0=BE=D0=B2=D0=B5=D1=80=D0=BA=D0=B8 =D1=82=D0=B8=D0=BF=
=D0=B0 =D1=84=D0=B0=D0=B9=D0=BB=D0=B0 =D0=B8 =D1=81=D1=80=D0=B0=D0=B2=D0=BD=
=D0=B5=D0=BD=D0=B8=D1=8F =D0=B7=D0=BD=D0=B0=D1=87=D0=B5=D0=BD=D0=B8=D0=B9
... or PHP's quoted_printable_encode, which gives the exact same output:
$ php -r '$a="test — UNIX-утилита для проверки типа файла и сравнения значений"; echo quoted_printable_encode($a)."\n";'
test =E2=80=94 UNIX-=D1=83=D1=82=D0=B8=D0=BB=D0=B8=D1=82=D0=B0 =D0=B4=D0=BB=
=D1=8F =D0=BF=D1=80=D0=BE=D0=B2=D0=B5=D1=80=D0=BA=D0=B8 =D1=82=D0=B8=D0=BF=
=D0=B0 =D1=84=D0=B0=D0=B9=D0=BB=D0=B0 =D0=B8 =D1=81=D1=80=D0=B0=D0=B2=D0=BD=
=D0=B5=D0=BD=D0=B8=D1=8F =D0=B7=D0=BD=D0=B0=D1=87=D0=B5=D0=BD=D0=B8=D0=B9
So, to test, I make a text file called test.eml, and try to simply wrap this output in the =?UTF-8?Q? ... ?= tags for the Subject: line, making sure that line endings are CRLF \r\n:
Message-Id: <4c428d27a41043e2b2b07e@example.com>
Subject: =?UTF-8?Q?test =E2=80=94 UNIX-=D1=83=D1=82=D0=B8=D0=BB=D0=B8=D1=82=D0=B0 =D0=B4=D0=BB=
=D1=8F =D0=BF=D1=80=D0=BE=D0=B2=D0=B5=D1=80=D0=BA=D0=B8 =D1=82=D0=B8=D0=BF=
=D0=B0 =D1=84=D0=B0=D0=B9=D0=BB=D0=B0 =D0=B8 =D1=81=D1=80=D0=B0=D0=B2=D0=BD=
=D0=B5=D0=BD=D0=B8=D1=8F =D0=B7=D0=BD=D0=B0=D1=87=D0=B5=D0=BD=D0=B8=D0=B9?=
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
Hello world
... but if I open this in Thunderbird, I get a corrupt output:
I've read somewhere that multiline in long header fields is covered by RFC0822 "LONG HEADER FIELDS", and basically, the line ending should be followed by a space. So I indent the continuation lines by one space:
Message-Id: <4c428d27a41043e2b2b07e@example.com>
Subject: =?UTF-8?Q?test =E2=80=94 UNIX-=D1=83=D1=82=D0=B8=D0=BB=D0=B8=D1=82=D0=B0 =D0=B4=D0=BB=
=D1=8F =D0=BF=D1=80=D0=BE=D0=B2=D0=B5=D1=80=D0=BA=D0=B8 =D1=82=D0=B8=D0=BF=
=D0=B0 =D1=84=D0=B0=D0=B9=D0=BB=D0=B0 =D0=B8 =D1=81=D1=80=D0=B0=D0=B2=D0=BD=
=D0=B5=D0=BD=D0=B8=D1=8F =D0=B7=D0=BD=D0=B0=D1=87=D0=B5=D0=BD=D0=B8=D0=B9?=
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
Hello world
... and I get a slighly different subject in Thunderbird, but still corrupt:

Now, if I delete =\r\n from the first three continuation lines, so the subject is all in one line:
Message-Id: <4c428d27a41043e2b2b07e@example.com>
Subject: =?UTF-8?Q?test =E2=80=94 UNIX-=D1=83=D1=82=D0=B8=D0=BB=D0=B8=D1=82=D0=B0 =D0=B4=D0=BB=D1=8F =D0=BF=D1=80=D0=BE=D0=B2=D0=B5=D1=80=D0=BA=D0=B8 =D1=82=D0=B8=D0=BF=D0=B0 =D1=84=D0=B0=D0=B9=D0=BB=D0=B0 =D0=B8 =D1=81=D1=80=D0=B0=D0=B2=D0=BD=D0=B5=D0=BD=D0=B8=D1=8F =D0=B7=D0=BD=D0=B0=D1=87=D0=B5=D0=BD=D0=B8=D0=B9?=
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
Hello world
... then actually Thunderbird shows the subject line well:
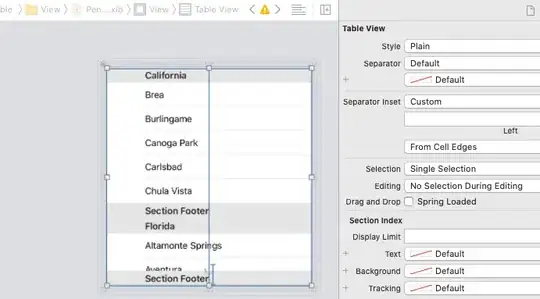
... but then my header is in conflict with the recommendation from RFC 2822 - 2.1.1. Line Length Limits which says "Each line of characters MUST be no more than 998 characters, and SHOULD be no more than 78 characters, excluding the CRLF."; specifically the line limit of 78 characters.
So, how can I obtain the proper multi-line quoted-printable representation of an UTF-8 Subject header string, so I can use it in an .eml file split at 78 characters - and have Thunderbird correctly read it?

{kind=link}