I am using ItextSharp and c#, asp.net MVC to generate a PDF report. However, when I generate the report the PDF comes back as blank (apart from a header which is working fine). I would love your input.
The code that generates the report is as follows:
using (var writer = PdfWriter.GetInstance(doc, ms))
{
// This sorts out the Header and Footer parts.
var headerFooter = new ReportHeaderFooter(reportsAccessor);
writer.PageEvent = headerFooter;
var rootPath = ConfigurationManager.AppSettings["SaveFileRootPath"];
string html = File.ReadAllText(rootPath + "/reports/report.html");
// Perform the parsing to PDF
doc.Open();
// The html needs to be sorted before this call.
StringReader sr = new StringReader(html);
XMLWorkerHelper.GetInstance().ParseXHtml(writer, doc, sr);
doc.Close();
writer.Close();
res = ms.ToArray();
}
I know there is a lot hidden, but for arguments sake an example of the HTML that this generates and puts in the StringReader is here:
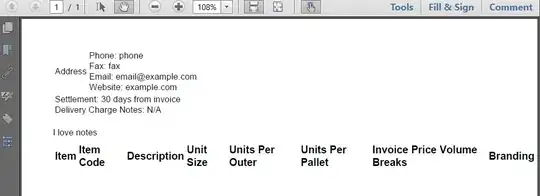
<table style="font-size:10pt">
<tr>
<td rowspan="4"> Address<br/> </td>
<td>Phone: phone</td>
</tr>
<tr>
<td>Fax: fax</td>
</tr>
<tr>
<td>Email: email@example.com</td>
</tr>
<tr>
<td>Website: example.com</td>
</tr>
<table>
<table style="font-size:10pt; width:100%">
<tr style="width:50%">
<td>Settlement: 30 days from invoice</td>
</tr>
<tr>
<td>Delivery Charge Notes: N/A</td>
</tr>
</table>
<p style="width:100%; font-size:10pt">
I love notes</p>
<table>
<tr style="font-weight:bold">
<td>Item</td>
<td>Item Code</td>
<td>Description</td>
<td>Unit Size</td>
<td>Units Per Outer</td>
<td>Units Per Pallet</td>
<td>Invoice Price Volume Breaks</td>
<td>Branding</td>
<td>Notes</td>
</tr>
</table>
However, this html generates a nice blank PDF file (not what I want). I can't see what might be wrong with this and would love some input in to two things:
[1] Why the report is blank [2] If this is an error in the parsing, why it doesn't come up with an error and instead a blank report (is there a setting or argument I can set that will throw errors which are much more useful than blank reports?)
UPDATE: I have added the code for the header/footer
public string HeaderTitle { get; set; } public IReportsAccessor ReportsAccessor { get; set; } public ReportHeaderFooter(IReportsAccessor reportsAccessor) { this.ReportsAccessor = reportsAccessor; }
public override void OnStartPage(PdfWriter writer, Document document)
{
base.OnStartPage(writer, document);
var rootPath = ConfigurationManager.AppSettings["SaveFileRootPath"];
GetReportImageResult imgInfo = ReportsAccessor.GetImage(4);
byte[] header_img = imgInfo.ReportImage;
string logoFn = rootPath + "/tmp/logo.png";
File.WriteAllBytes(logoFn, header_img);
string html = File.ReadAllText(rootPath + "/reports/report_header.html");
html = html.Replace("{{ title }}", HeaderTitle);
html = html.Replace("{{ logo_img }}", logoFn);
StringReader sr = new StringReader(html);
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}