This is rather a weird problem.
A have a code of back propagation which works perfectly, like this:
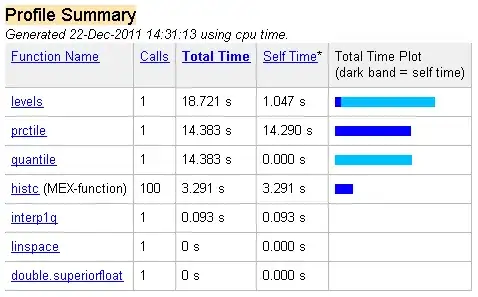
Now, when I do batch learning I get wrong results even if it concerns just a simple scalar function approximation.
After training the network produces almost the same output for all input patterns.
By this moment I've tried:
- Introduced bias weights
- Tried with and without updating of input weights
- Shuffled the patterns in batch learning
- Tried to update after each pattern and accumulating
- Initialized weights in different possible ways
- Double-checked the code 10 times
- Normalized accumulated updates by the number of patterns
- Tried different layer, neuron numbers
- Tried different activation functions
- Tried different learning rates
- Tried different number of epochs from 50 to 10000
- Tried to normalize the data
I noticed that after a bunch of back propagations for just one pattern, the network produces almost the same output for large variety of inputs.
When I try to approximate a function, I always get just line (almost a line). Like this:
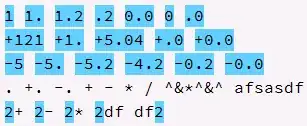
Related question: Neural Network Always Produces Same/Similar Outputs for Any Input And the suggestion to add bias neurons didn't solve my problem.
I found a post like:
When ANNs have trouble learning they often just learn to output the
average output values, regardless of the inputs. I don't know if this
is the case or why it would be happening with such a simple NN.
which describes my situation closely enough. But how to deal with it?
I am coming to a conclusion that the situation I encounter has the right to be. Really, for each net configuration, one may just "cut" all the connections up to the output layer. This is really possible, for example, by setting all hidden weights to near-zero or setting biases at some insane values in order to oversaturate the hidden layer and make the output independent from the input. After that, we are free to adjust the output layer so that it just reproduces the output as is independently from the input. In batch learning, what happens is that the gradients get averaged and the net reproduces just the mean of the targets. The inputs do not play ANY role.