I am getting an whole html page from an ajax request as text (xmlhttp.responseText)
Then filtering the text to extract a html form from that text and everything inside that form.
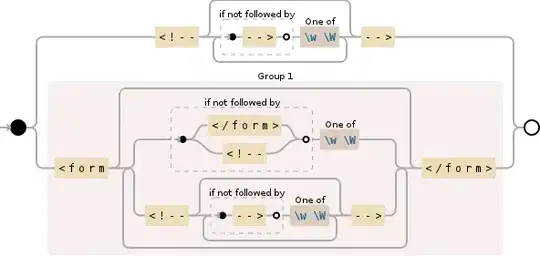
I wrote an regex :
text.match(/(<form[\W\w]*<\/form>)/gim)
As i am not an expert in regex, so i cant be sure will it work in every scenario and get everything inside the form tag?
Is there a better way that i can say everything in regex? so that the regex will look like
text.match(/(<form[__everything_syntaxt_here__]*<\/form>)/gim)