I have two very large strings and I am trying to find out their Longest Common Substring.
One way is using suffix trees (supposed to have a very good complexity, though a complex implementation), and the another is the dynamic programming method (both are mentioned on the Wikipedia page linked above).
Using dynamic programming
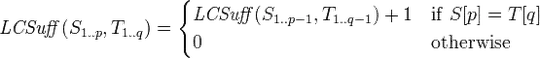
The problem is that the dynamic programming method has a huge running time (complexity is O(n*m), where n and m are lengths of the two strings).
What I want to know (before jumping to implement suffix trees): Is it possible to speed up the algorithm if I only want to know the length of the common substring (and not the common substring itself)?