If you have GNU Parallel you can run:
ls | parallel -N3 "echo item i: {1}; echo item j: {2}; echo item k: {3}"
All new computers have multiple cores, but most programs are serial in nature and will therefore not use the multiple cores. However, many tasks are extremely parallelizeable:
- Run the same program on many files
- Run the same program for every line in a file
- Run the same program for every block in a file
GNU Parallel is a general parallelizer and makes is easy to run jobs in parallel on the same machine or on multiple machines you have ssh access to.
If you have 32 different jobs you want to run on 4 CPUs, a straight forward way to parallelize is to run 8 jobs on each CPU:
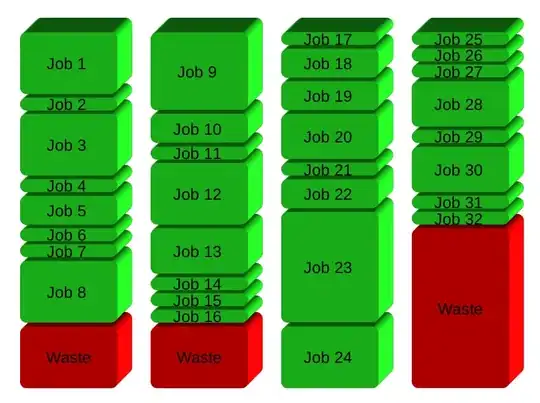
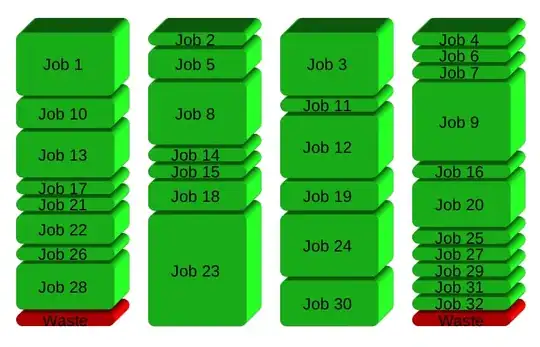
GNU Parallel instead spawns a new process when one finishes - keeping the CPUs active and thus saving time:
Installation
A personal installation does not require root access. It can be done in 10 seconds by doing this:
(wget -O - pi.dk/3 || curl pi.dk/3/ || fetch -o - http://pi.dk/3) | bash
For other installation options see http://git.savannah.gnu.org/cgit/parallel.git/tree/README
Learn more
See more examples: http://www.gnu.org/software/parallel/man.html
Watch the intro videos: https://www.youtube.com/playlist?list=PL284C9FF2488BC6D1
Walk through the tutorial: http://www.gnu.org/software/parallel/parallel_tutorial.html
Sign up for the email list to get support: https://lists.gnu.org/mailman/listinfo/parallel