I have file names in this format :
INC_2AB_22BA_1300435674_218_19-May-2014_13-09-59.121._OK
INC_2EE_22RE_1560343444_119_11-Jun-2014_15-21-32.329._OK
INC_2CD_22HY_1652323334_312_21-Jan-2014_11-15-48.291._OK
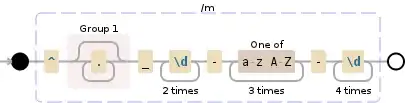
I want to extract the name before the date part. For instance, anything before _19-May-2014_13-09-59.121._OK is desired in first file yielding INC_2AB_22BA_1300435674_218
I tried lookback method but unable to wrap my head around this at the moment.
Essential, trying to match this pattern _[0-9]-[aA-bB]-*