Continuing on from our previous post, let's answer one question at a time.
Question #1
Usually, you use one I-frame and denote this as the reference frame. Once you use this, for each 8 x 8 block that's in your reference frame, you take a look at the next frame and figure out where this 8 x 8 block best moved in this next frame. You describe this displacement as a motion vector and you construct a P-frame that consists of this information. This tells you where the 8 x 8 block from the reference frame best moved in this frame.
Now, the next question you may be asking is how many frames is it going to take before we decide to use another reference frame? This is entirely up to you, and you set this up in your decoder settings. For digital broadcast and DVD storage, it is recommended that you generate an I-frame every 0.5 seconds or so. Assuming 24 frames per second, this means that you would need to generate an I-frame every 12 frames. This Wikipedia article was where I got this reference.
As for the intra-coding modes, these tell the encoder in what direction you should look for when trying to find the best matching block. Actually, take a look at this paper that talks about the different prediction modes. Take a look at Figure 1, and it provides a very nice summary of the various prediction modes. In fact, there are nine all together. Also take a look at this Wikipedia article to get better pictorial representations of the different mechanisms of prediction as well. In order to get the best accuracy, they also do subpixel estimation at a 1/4 pixel accuracy by doing bilinear interpolation in between the pixels.
I'm not sure whether or not you need to implement just motion compensation with P-frames, or if you need B frames as well. I'm going to assume you'll be needing both. As such, take a look at this diagram I pulled off of Wikipedia:
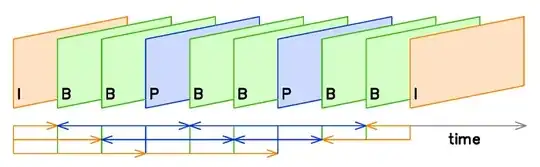
Source: Wikipedia
This is a very common sequence for encoding frames in your video. It follows the format of:
IBBPBBPBBI...
There is a time axis at the bottom that tells you the sequence of frames that get sent to the decoder once you encode the frames. I-frames need to be encoded first, followed by P-frames, and then B-frames. A typical sequence of frames that are encoded in between the I-frames follow this format that you see in the figure. The chunk of frames in between I-frames is what is known as a Group of Pictures (GOP). If you remember from our previous post, B-frames use information from ahead and from behind its current position. As such, to summarize the timeline, this is what is usually done on the encoder side:
- The I-frame is encoded, and then is used to predict the first P-frame
- The first I-frame and the first P-frame are then used to predict the first and second B-frame that are in between these frames
- The second P-frame is predicted using the first P-frame, and the third and fourth B-frames are created using information between the first P-frame and the second P-frame
- Finally, the last frame in the GOP is an I-frame. This is encoded, then information between the second P-frame and the second I-frame (last frame) are used to generate the fifth and sixth B-frames
Therefore, what needs to happen is that you send I-frames first, then the P-frames, and then the B-frames after. The decoder has to wait for the P-frames before the B-frames can be reconstructed. However, this method of decoding is more robust because:
- It minimizes the problem of possible uncovered areas.
- P-frames and B-frames need less data than I-frames, so less data is transmitted.
However, B-frames will require more motion vectors, and so there will be some higher bit rates here.
Question #2
Honestly, what I have seen people do is do a simple Sum-of-Squared Differences between one frame and another to compare similarity. You take your colour components (whether it be RGB, YUV, etc.) for each pixel from one frame in one position, subtract these with the colour components in the same spatial location in the other frame, square each component and add them all together. You accumulate all of these differences for every location in your frame. The higher the value, the more dissimilar this is between the one frame and the next.
Another measure that is well known is called Structural Similarity where some statistical measures such as mean and variance are used to assess how similar two frames are.
There are a whole bunch of other video quality metrics that are used, and there are advantages and disadvantages when using any of them. Rather than telling you which one to use, I defer you to this Wikipedia article so you can decide which one to use for yourself depending on your application. This Wikipedia article describes a whole bunch of similarity and video quality metrics, and the buck doesn't stop there. There is still on-going research on what numerical measures best capture the similarity and quality between two frames.
Question #3
When searching for the best block from an I-frame that has moved in a P-frame, you need to restrict the searching to a finite sized windowed area from the location of this I-frame block because you don't want the encoder to search all of the locations in the frame. This would simply be too computationally intensive and would thus make your decoder slow. I actually mentioned this in our previous post.
Using one pixel to search for another pixel in the next frame is a very bad idea because of the minuscule amount of information that this single pixel contains. The reason why you compare blocks at a time when doing motion estimation is because usually, blocks of pixels have a lot of variation inside the blocks which are unique to the block itself. If we can find this same variation in another area in your next frame, then this is a very good candidate that this group of pixels moved together to this new block. Remember, we're assuming that the frame rate for video is adequately high enough so that most of the pixels in your frame either don't move at all, or move very slowly. Using blocks allows the matching to be somewhat more accurate.
Blocks are compared at a time, and the way blocks are compared is using one of those video similarity measures that I talked about in the Wikipedia article I referenced. You are certainly correct in that doing this for 30 frames would indeed be slow, but there are implementations that exist that are highly optimized to do the encoding very fast. One good example is FFMPEG. In fact, I use FFMPEG at work all the time. FFMPEG is highly customizable, and you can create an encoder / decoder that takes advantage of the architecture of your system. I have it set up so that encoding / decoding uses all of the cores on my machine (8 in total).
This doesn't really answer the actual block comparison itself. Actually, the H.264 standard has a bunch of prediction mechanisms in place so that you're not looking at all of the blocks in an I-frame to predict the next P-frame (or one P-frame to the next P-frame, etc.). This alludes to the different prediction modes in the Wikipedia article and in the paper that I referred you to. The encoder is intelligent enough to detect a pattern, and then generalize an area of your image where it believes that this will exhibit the same amount of motion. It skips this area and moves onto the next.
This assignment (in my opinion) is way too broad. There are so many intricacies in doing motion prediction / compensation that there is a reason why most video engineers already use available tools to do the work for us. Why invent the wheel when it has already been perfected, right?
I hope this has adequately answered your questions. I believe that I have given you more questions than answers really, but I hope that this is enough for you to delve into this topic further to achieve your overall goal.
Good luck!