Talend does provide a dynamic mapping tool. It's called the tMap or tXmlMap for XML data.
There's also the tHMap (Hierarchical Mapping tool) which is a lot more powerful but I've yet to use it at all because it's very raw in the version of Talend I'm using (5.4) but should be more usable in 5.5.
Your best approach here may be to use a tMap after each of your components to standardise the schema of your data.
First you should pick what the output schema should look like (this could be the same as one of your current schemas or something entirely different if necessary) and then simply copy and paste the schema to the output table of each tMap. Then map the relevant data across.
An example job may look something like this:

Where the schemas and the contained data for each "file" (I'm using tFixedFlowInput components to hardcode the data to the job rather than read in a file but the premise is the same) is as following:
File 1:
 File 2:
File 2:
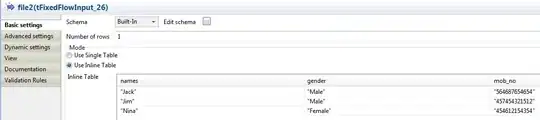 File 3:
File 3:
And they are then mapped to match the schema of the first "file":
File 1:
 File 2:
File 2:
 File 3:
File 3:

Notice how the first tMap configuration shows no changes as we are keeping the schema exactly the same.
Now that our inputs all share the same schema we can use a tUnite component to union (much like SQL's UNION operator) the data.
After this we then also take one final step and use a tReplace component so that we can easily standardise the "sex" field to M or F:
And then lastly I output that to the console but this could be output to any available output component.
For a truly dynamic option without having to predefine the mapping you would need to read in all of your data with a dynamic schema. You could then parse the structure out into a defined output.
In this case you could read the data from your files in as a dynamic schema (single column) and then drop it straight into a temporary database table. Talend will automatically create the columns as per the headers in the original file.
From here you could then use a transformation mapping file and the databases' data dictionary to extract the data in the source columns and map it directly to the output columns.