Here's my query (it's automatically generated):
SELECT
sn.name,
sa.house_number,
sa.entrance,
pc.postal_code,
ci.name,
mu.name,
co.name,
sa.latitude,
sa.longitude
FROM
street_addresses AS sa INDEXED BY sa_unique_address
INNER JOIN street_names AS sn ON sa.street_name = sn.id
INNER JOIN postal_codes AS pc ON sa.postal_code = pc.id
INNER JOIN cities AS ci ON sa.city = ci.id
INNER JOIN municipalities AS mu ON sa.municipality = mu.id
INNER JOIN counties AS co ON mu.county = co.id
WHERE
sn.name GLOB "THORLEIF HAUGS VEI" AND
sa.house_number = 23
ORDER BY pc.postal_code ASC, sn.name ASC, sa.house_number ASC, sa.entrance ASC
LIMIT 0, 100;
The GLOB is there because this is for a search function that must support wildcards. This query runs perfectly fast on Linux, both in the sqlite3 command line tool as well as in ruby-sqlite3. When on Windows, it runs super fast in the sqlite3 command line tool, but it takes several seconds to execute in Ruby. If I replace the GLOB with =, the issue disappears.
This is how I tested the query on Windows:
> db = SQLite3::Database.open("norway.db")
> sql = File.load("test.sql")
> db.execute(sql) # SLOW!!!
> db.execute(sql.sub("GLOB", "=")) # Super mega fast!
I've run EXPLAIN QUERY PLAN both in the command line tool and through Ruby, both of which indicate that the indexes are being used:
selectid order from detail ---------- ---------- ---------- -------------------------------------------------------------------------------- 0 0 1 SEARCH TABLE street_names AS sn USING COVERING INDEX sn_name (name>? AND name<?) 0 1 0 SEARCH TABLE street_addresses AS sa USING INDEX sa_unique_address (street_name=? 0 2 3 SEARCH TABLE cities AS ci USING INTEGER PRIMARY KEY (rowid=?) 0 3 2 SEARCH TABLE postal_codes AS pc USING INTEGER PRIMARY KEY (rowid=?) 0 4 4 SEARCH TABLE municipalities AS mu USING INTEGER PRIMARY KEY (rowid=?) 0 5 5 SEARCH TABLE counties AS co USING INTEGER PRIMARY KEY (rowid=?) 0 0 0 USE TEMP B-TREE FOR ORDER BY
This is the database I'm using: norway.db. The link will certainly be broken at some point, but hopefully we've reached a solution by then.
I've done some profiling:
result = RubyProf.profile {
data = db.execute(sql)
}
Here are the results:
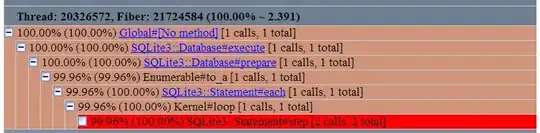
Here's the call graph in text format.
These lines are of particular interest:
%total %self total self wait child calls Name
2.395 2.395 0.000 0.000 2/2 Kernel#loop
100.00% 100.00% 2.395 2.395 0.000 0.000 2 SQLite3::Statement#step (ruby_runtime:0} ruby_runtime:0
0.000 0.000 0.000 0.000 2/2 SQLite3::Database#encoding
The profiler points me to statement.rb:108, which points me to the C function step, which is defined in statement.c:107.
So is this a Windows specific problem in the C code? Is it a SQLite 3 bug or a bug in the ruby library? Any ideas on what I can do to resolve this issue?
EDIT: Odd, reducing the query to this makes the issue disappear, even though the GLOB is still there:
SELECT
sn.name,
sa.house_number
FROM
street_addresses AS sa INDEXED BY sa_unique_address
INNER JOIN street_names AS sn ON sa.street_name = sn.id
WHERE
sn.name GLOB "THORLEIF HAUGS VEI" AND
sa.house_number = 23
ORDER BY sn.name ASC, sa.house_number ASC, sa.entrance ASC
LIMIT 0, 100;
EXPLAIN QUERY PLAN output:
selectid order from detail ---------- ---------- ---------- --------------------------------------------------------------------------------------------- 0 0 1 SEARCH TABLE street_names AS sn USING COVERING INDEX sn_name (name>? AND name<?) 0 1 0 SEARCH TABLE street_addresses AS sa USING COVERING INDEX sa_unique_address (street_name=? AND house_number=?)
Though I'm not sure that matters. As I said, the speed issue seems to be in sqlite3-ruby, not sqlite3 itself.
EDIT: Odder still, removing sorting from the query also solves the speed problem! This query is fast as lightning on Windows sqlite3-ruby:
SELECT
sn.name,
sa.house_number,
sa.entrance,
pc.postal_code,
ci.name,
mu.name,
co.name,
sa.latitude,
sa.longitude
FROM
street_addresses AS sa INDEXED BY sa_unique_address
INNER JOIN street_names AS sn ON sa.street_name = sn.id
INNER JOIN postal_codes AS pc ON sa.postal_code = pc.id
INNER JOIN cities AS ci ON sa.city = ci.id
INNER JOIN municipalities AS mu ON sa.municipality = mu.id
INNER JOIN counties AS co ON mu.county = co.id
WHERE
sn.name GLOB "THORLEIF HAUGS VEI" AND
sa.house_number = 23
LIMIT 0, 100;
What the heck is going on here!? Here's the EXPLAIN QUERY PLAN output:
selectid order from detail ---------- ---------- ---------- -------------------------------------------------------------------------------- 0 0 1 SEARCH TABLE street_names AS sn USING COVERING INDEX sn_name (name>? AND name<?) 0 1 0 SEARCH TABLE street_addresses AS sa USING INDEX sa_unique_address (street_name=? 0 2 2 SEARCH TABLE postal_codes AS pc USING INTEGER PRIMARY KEY (rowid=?) 0 3 3 SEARCH TABLE cities AS ci USING INTEGER PRIMARY KEY (rowid=?) 0 4 4 SEARCH TABLE municipalities AS mu USING INTEGER PRIMARY KEY (rowid=?) 0 5 5 SEARCH TABLE counties AS co USING INTEGER PRIMARY KEY (rowid=?)