The requirement for construction of distribution with given mean and deviation is impossible to be satisfied if deviation is greater than distance from mean to any bound. To see this let's first notice that in sample
x1, x2, ..., mean, ... , xn
with mean mi = sum(x_i)/n
deviation is bounded:
dev < xmax - mean, and dev < mean - xmin. Without providing formula it is quite intuitive since the meaning of it is average deviation from the mean - how could it be greater than the maximum deviation ( max of ( mean - xmin, xmax - mean)) from the mean?
So if deviation is greater than max of [ mean - xmin, xmax - mean] then we have error. Now let's take a look at two other cases:
when it is in range (0, min of[ mean - xmin, xmax - mean])
and when it is in range (0, max of[ mean - xmin, xmax - mean]) but
not in range (0, min of[ mean - xmin, xmax - mean]), ( so it is
greater than one bound, but less then other one)
When it is in range (0, min of[ mean - xmin, xmax - mean])
Bernoulli distribution
This is simple to construct some distribution that yields sample with mean mi and deviation d with all values in range [xmin, xmax]. The simple case of two points distribution with
x1 = mi - d, x2 = mi + d
has the expectation of mi and deviation of d.
#include <boost/random.hpp>
#include <boost/random/bernoulli_distribution.hpp>
double generate_from_bernoulli_distribution(double mi, double d,
double a, double b) {
if (b <= a || d < 0) throw std::out_of_range( "invalid parameters");
if (d > std::min(mi - a, b - mi)) throw std::out_of_range( " invalid
standard deviation");
double x1 = mi - d, x2 = mi + d;
boost::mt19937 rng; // I don't seed it on purpouse (it's not relevant)
boost::bernoulli_distribution<> bd;
boost::variate_generator<boost::mt19937&,
boost::bernoulli_distribution<> > var_ber( rng, bd);
double bernoulli = var_ber();
return ( x1 + bernoulli * 2 * d); // return x1 on 0, or x2 on 1
}
void generate_n_from_bernoulli_distribution( double mi, double d, double a,
double b, std::vector<double>& res, int n) {
if (b <= a || d < 0) throw std::out_of_range( "invalid parameters");
if (d > std::min(mi - a, b - mi)) throw std::out_of_range( " invalid
standard deviation");
double x1 = mi - d, x2 = mi + d;
boost::mt19937 rng; // I don't seed it on purpouse (it's not relevant)
boost::bernoulli_distribution<> bd;
boost::variate_generator<boost::mt19937&,
boost::bernoulli_distribution<> > var_ber( rng, bd);
int i = 0;
for (; i < n; ++i) {
double bernoulli = var_ber();
res.push_back( x1 + bernoulli * 2 * d); // push_back x1 on 0, or x2 on 1
}
}
usage:
/*
*
*/
int main()
{
double rc = generate_from_bernoulli_distribution( 4, 1, 0, 10);
std::vector<double> sample;
generate_n_from_bernoulli_distribution( 4, 1, 0, 10, sample, 100);
return 0;
}
The case of Bernoulli, two points distribution is the first to consider as it has the weakest requirements. Sometimes it will be possible to draw also from other distributions, for example from uniform distribution.
Uniform distribution
The first two moments of uniform distribution (the mean and variance) in terms of its range [a, b] are given by

where
a = mi - alpha
b = mi + alpha
alpha is any real number
So there are infote number of uniform distributions that yield mean mi. All of them are just centered over mi. Additional requirement, for a variance gives us single solution for a, b:
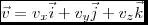
/**
* generates intervals for a uniform distribution
* with a given mean and deviation
* @param mi mean
* @param d deviation
* @param a left bound
* @param b right bound
* @return
*/
void uniform_distribution_intervals( double mi, double d, double& a, double& b) {
a = mi - d * std::sqrt(3.0);
b = mi + d * std::sqrt(3.0);
}
It is clear that not always it is possible to find uniform distribution for a given mi, d, which will have left bound greater than 0. In this case
uniform_distribution_intervals( 60/84, 1.7, a, b);
unfortunately returns a = -2.9444863728670914, b = 2.9444863728670914.
when it is in range (0, max of[ mean - xmin, xmax - mean]) but not in range (0, min of[ mean - xmin, xmax - mean])
left as useful exercise