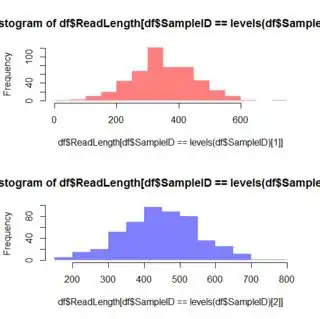
I want to plot a histogram of lengths based on locations. I am trying to overlay the histogram where data of one location is one color and the other location is a different color.
Here is the R code I have so far that just plots the histogram:
fasta<-read.csv('fastadata.csv',header = T)
norton<-fasta[fasta$SampleID == ">P.SC1Norton-28F",]
cod<-fasta[fasta$SampleID == ">P.SC4CapeCod-28F ",]
bins <- seq(200, 700, by=25)
hist(fasta[,3], breaks=bins, main="Histogram of ReadLengths of a set bin size for Cape Cod and Norton", xlab="ReadLengths")
I keep seeing ggplot used, but I am unsure how to use this function within one table and using the binning I used.
Output of dput(head(fasta)):
structure(list(SampleID = structure(c(2L, 2L, 2L, 2L, 2L, 2L), .Label = c(">P.SC1Norton-28F",">P.SC4CapeCod-28F"), class = "factor"), SeqName = structure(c(5674L, 5895L, 5731L, 5510L, 4461L, 5648L), .Label = c("IJO4WN203F00DQ", "IKTXKCP03HKQ5E"), class = "factor"), ReadLength = c(394L, 429L, 437L, 438L, 459L, 413L)), .Names = c("SampleID", "SeqName", "ReadLength"), row.names = c(NA, 6L), class = "data.frame")