So, I'm trying to make a program which turns a computer into a proxy using this. It all works well, except for gzip/deflate pages.
Whenever I try to uncompress, I get an InvalidDataException stating the magic number in the GzipHeader is incorrect.
I use this function:
private byte[] GZipUncompress(byte[] data)
{
using (var input = new MemoryStream(data))
{
input.Seek(0, SeekOrigin.Begin);
using (var gzip = new GZipStream(input, CompressionMode.Decompress))
using (var output = new MemoryStream())
{
output.Seek(0, SeekOrigin.Begin);
gzip.CopyTo(output);
return output.ToArray();
}
}
}
to decompress data. The error:

(source: gyazo.com)
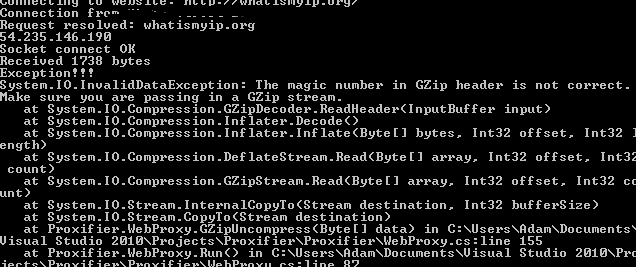{kind=link}
Any help would be appreciated.
EDIT: I seem to have gotten somewhere!
As usr suggested, I should write a HTTP parser to get the body and decompress that.
Before parsing: http://pastebin.com/Cb0E8WtT
After parsing: http://pastebin.com/k9e8wMvr
This is the method I use to get to the body:
private byte[] HTTParse(byte[] data)
{
string http = ascii.GetString(data);
char[] lineBreak = crlf.ToCharArray();
string[] parts = http.Split(lineBreak);
List<byte> res = new List<byte>();
for (int i = 1; i < parts.Length; i++)
{
if (i % 2 == 0)
{
Regex r = new Regex(@"(.)*: (.)*");
Regex htt = new Regex(@"HTT(.)*/(.)*.(.)* d{1,50} (.)*");
if (!r.IsMatch(parts[i]) && !htt.IsMatch(parts[i]))
{
//Console.WriteLine("[TEST] " + parts[i]);
res.AddRange(ascii.GetBytes(parts[i]));
res.AddRange(ascii.GetBytes("\r\n"));
}
}
}
return res.ToArray();
}
However, I still get an error saying "The magic number in GZip header is not correct. Make sure you are passing in a GZip stream."
EDIT (2): After copying an answer from here, I have managed to successfully uncompress the body.
The new problem: Firefox.

(source: gyazo.com)
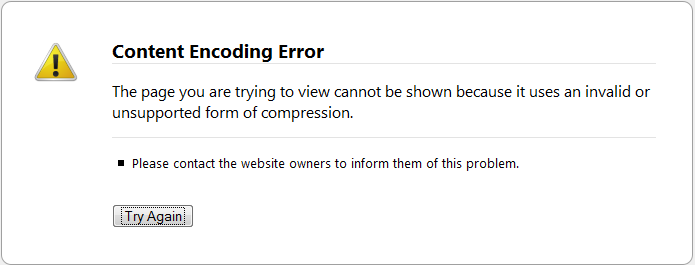{kind=link}
I'm now unsure whether or not I even needed to uncompress gzip pages..
Where have I gone wrong now?