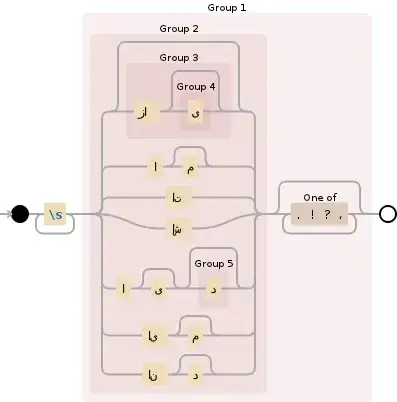
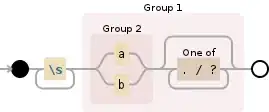
I have this Python regular expression code in Python 3 that I do not understand. I appreciate any help to explain what exactly it does with a few examples. The code is this:
# encoding=utf-8
import re
newline = re.sub(r'\s+(((زا(ی)?)?|ام?|ات|اش|ای?(د)?|ایم?|اند?)[\.\!\?\،]*)', r'\1 ', newline)