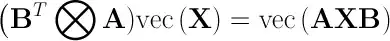I have an application that requires me to calculate some large Kronecker products of 2D matrices and multiply the result by large 2D matrices. I would like to implement this on a GPU in CUDA and would prefer to use a tuned library implementation for this, rather than writing my own (certainly suboptimal) Kronecker product. I have experience with CUDA, BLAS, LAPACK etc, but unfortunately there is no kron(A,B) function in the common GPU implementations (magma, cuBLAS, cula, etc).
I've searched for some solutions, but can't find a library that suits my needs. (The closest question on SO is parallel Kronecker tensor product on gpu using CUDA, but this looks like a custom solution to a special case, which won't suit my needs. I'm looking for Kronecker product that will work in the most general case.)
I have read that DGEMM in BLAS can be used to implement a Kronecker product. Is there a standard algorithm to implement a Kronecker product using DGEMM (or its single/complex variants)? It's seems to me that the only way would be to call DGEMM in a loop and tile the results into a larger matrix, which does not seem very efficient. Or, does anyone know another implementation or paper that might provide what I'm looking for?