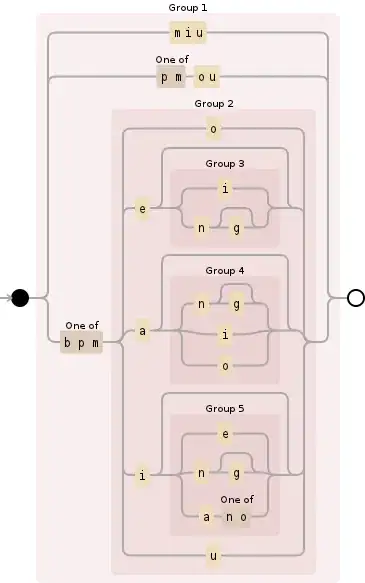
I'm looking for a regular expression that can correctly match valid pinyin (e.g. "sheng", "sou" (while ignoring invalid pinyin, e.g. "shong", "sei"). Most of the regex provided in the top Google results match invalid pinyin in some cases.
Obviously, no matter what approach one takes, this will be a monster regex, and I'm especially interested in the different approaches one could take to solve this problem. For example, "Optimizing a regular expression to parse chinese pinyin" uses lookbacks.
A table of valid pinyin can be found here: http://pinyin.info/rules/initials_finals.html