I am using ImageMagick to convert a digitalized PDF file to tiff. I use Tesseract to scan a small part of this document which is a number. My digitalized documents have a poor definition and sometime tesseract doesn't manage to read the right number. For example, it reads : 5550002845 for the number you can see in the picture.
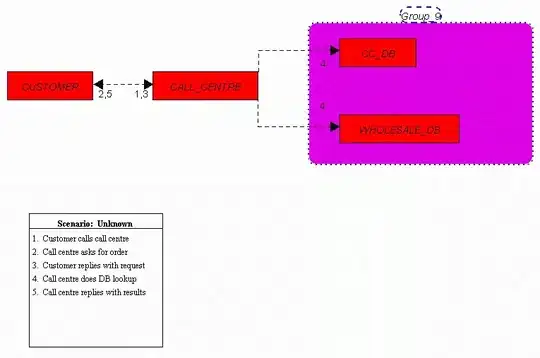
This picture was extracted from the PDF with the following command :
convert -quality 100 -density 300 temp.pdf -depth 8 -colorspace gray +matte +contrast +contrast temp.tiff
Is there anything better I can do to improve the image quality (of the Tesseract detection) ?
Regards