I was trying to parse some webpage's content using HTML::TreeBuilder and then do a manual XPath-like walk.
But I got something really weird.
This is the X-Path produced from the web page by Chrome's Developer Tools:
/html/body/table/tbody/tr/td[1]/table[3]/tbody/tr[1]/td[2]/
table[1]/tbody/tr[1]/td[2]/**table[9]**
That last inner table #9 is what I need - more specifically, a cell that has "click to view" text in it.
Here's the developer tools screenshot - notice that BODY tag only has one table under it:
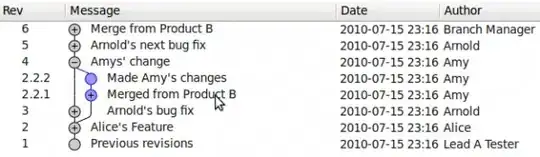
And if you drill down into that XPath you will see the element I seek (Notice it's really nested table within table within table - I included the TD element I seek):
HOWEVER, This is what HTML::TreeBuilder produced instead (Basically, a <body> tag containing 22 tags under it most of which are <table> tags:
DB<16> x $tree->tag
0 'body'
DB<17> x map {$_->tag} $tree->content_list
0 'table'
1 'table'
2 'table'
3 'table'
4 'table'
5 'table'
6 'table'
7 'table'
8 'table'
9 'table'
10 'table'
11 'table'
12 'table'
13 'table'
14 'table'
15 'table'
16 'table'
17 'table'
18 'table'
19 'script'
20 'table'
21 'table'
And as you can see, the 8th table under BODY TAG contains the element I want
DB<37> foreach my $c (0 .. $tree->content_list-1) {
if (($tree->content_list)[$c]->as_HTML =~ /click to view/)
{print $c+1}}
9