Suppose A join B on A.a=B.a, and both of them are big tables. Hive will process this join operation through common join. The execution graph(given by facebook):
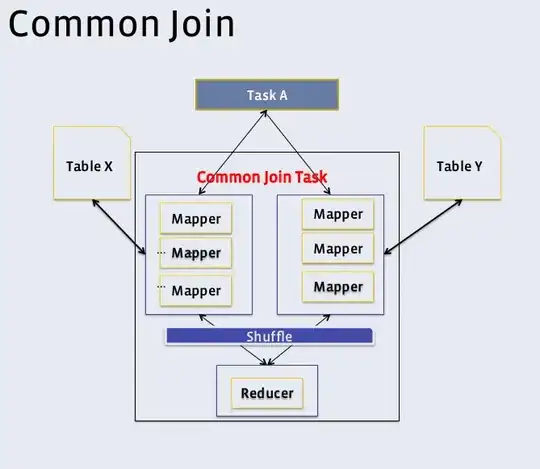
But I'm confused by this graph, is there only on reducer?
In my understanding, the map output key is table_name_tag_prefix+join_key. But in partition phase, it still uses the join_key to partition the records. In reduce phase, each reducer reads the <join_key,value> which have the same join key, the reducer needn't read all map splits.