I wrote some RegEx to play with spaces in strings, and it works beautifully, except for when I come across this character: " " instead of " ". You probably think I'm crazy, but apparently they're different. Check out this RegEx app (oddly enough, it often crashes it):
When I use the weird space:
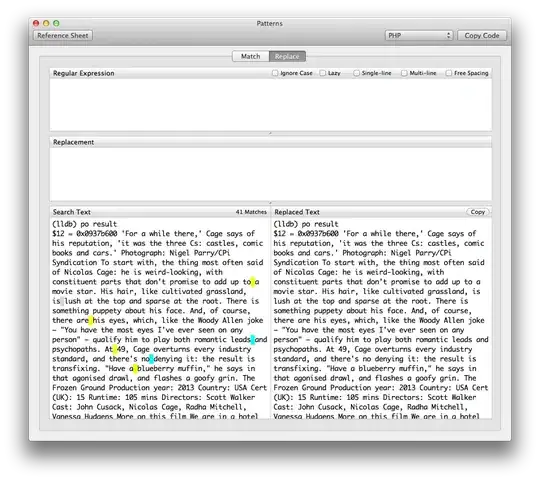
When I use a normal space:
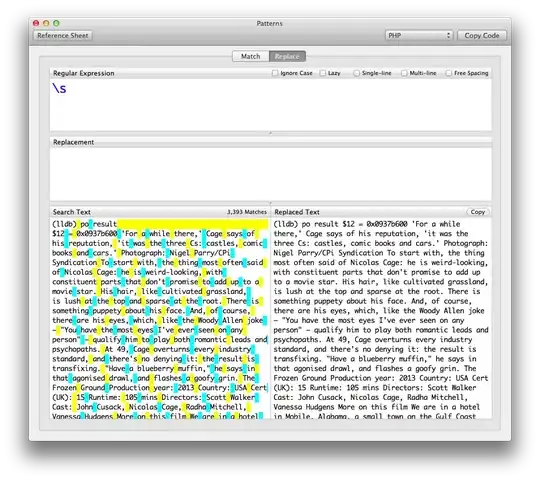
As you can see, there are many more spaces detected here, but it doesn't detect the weird spaces.
What is this space? How do I get rid of it?