I have a data of protein-protein interactions in a data frame entitled: s1m. Each DB and AD pair make an interaction and I can plot it as well:
> head(s1m)
DB_num AD_num
[1,] 2 8153
[2,] 7 3553
[3,] 8 4812
[4,] 13 7838
[5,] 24 3315
[6,] 24 6012
Plot of the data looks like:
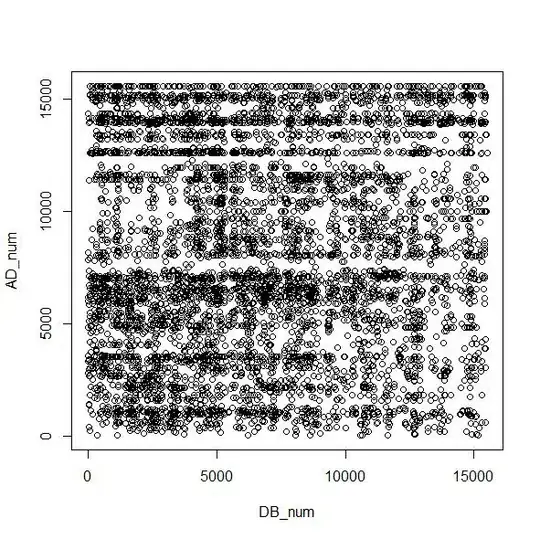
I then used code I found on this site to plot filled contour lines:
## compute 2D kernel density, see MASS book, pp. 130-131
require(MASS)
z <- kde2d(s1m[,1], s1m[,2], n=50)
plot(s1m, xlab="X label", ylab="Y label", pch=19, cex=.4)
filled.contour(z, drawlabels=FALSE, add=TRUE)
It gave me the resulting image(minus the scribbles):

MY QUESTION: I need to annotate each line of data in the original s1m data frame with a number corresponding to its height on the contour map (hence my scribbles on the image above). I think the list z has the values I am looking for, but I am not sure.
In the end I would want my data to hopefully look something like this so I could study the protein interactions in groups:
DB_num AD_num height
[1,] 2 8153 1
[2,] 7 3553 1
[3,] 8 4812 3
[4,] 13 7838 6
[5,] 24 3315 2
[6,] 24 6012 etc.