I have a string that begins with one or more occurrences of the sequence "Re:". This "Re:" can be of any combinations, for ex. Re<any number of spaces>:, re:, re<any number of spaces>:, RE:, RE<any number of spaces>:, etc.
Sample sequence of string : Re: Re : Re : re : RE: This is a Re: sample string.
I want to define a java regular expression that will identify and strip off all occurrences of Re:, but only the ones at the beginning of the string and not the ones occurring within the string.
So the output should look like This is a Re: sample string.
Here is what I have tried:
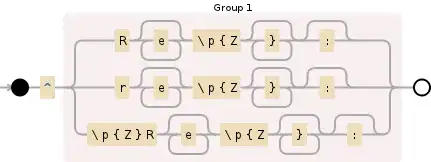
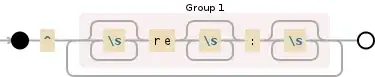
String REGEX = "^(Re*\\p{Z}*:?|re*\\p{Z}*:?|\\p{Z}Re*\\p{Z}*:?)";
String INPUT = title;
String REPLACE = "";
Pattern p = Pattern.compile(REGEX);
Matcher m = p.matcher(INPUT);
while(m.find()){
m.appendReplacement(sb,REPLACE);
}
m.appendTail(sb);
I am using p{Z} to match whitespaces(have found this somewhere in this forum, as Java regex does not identify \s).
The problem I am facing with this code is that the search stops at the first match, and escapes the while loop.