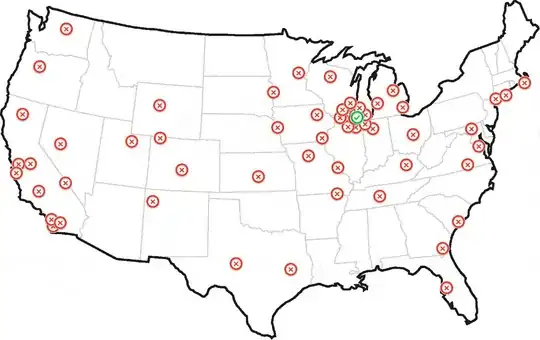
A simple mixture model seems to work pretty well for this problem.
In general, to get a point that minimizes the distance to all other points in a dataset, you can just take the mean. In this case, you want to find a point that minimizes the distance from a subset of concentrated points. If you postulate that a point can either come from the concentrated set of points of interest or from a diffuse set of background points, then this gives a mixture model.
I have included some python code below. The concentrated area is modeled by a high-precision normal distribution and the background point are modeled by either a low-precision normal distribution or a uniform distribution over a bounding box on the dataset (there is a line of code that can be commented out to switch between these options). Also, mixture models can be somewhat unstable, so running the EM algorithm a few times with random initial conditions and choosing the run with the highest log-likelihood gives better results.
If you are actually looking at airplanes, then adding some sort of time dependent dynamics will probably improve your ability to infer the home base immensely.
I would also be wary of Rossimo's formula because it includes some pretty-strong assumptions about crime distributions.
#the dataset
sdata='''41.892694,-87.670898
42.056048,-88.000488
41.941744,-88.000488
42.072361,-88.209229
42.091933,-87.982635
42.149994,-88.133698
42.171371,-88.286133
42.23241,-88.305359
42.196811,-88.099365
42.189689,-88.188629
42.17646,-88.173523
42.180531,-88.209229
42.18168,-88.187943
42.185496,-88.166656
42.170485,-88.150864
42.150634,-88.140564
42.156743,-88.123741
42.118555,-88.105545
42.121356,-88.112755
42.115499,-88.102112
42.119319,-88.112411
42.118046,-88.110695
42.117791,-88.109322
42.182189,-88.182449
42.194145,-88.183823
42.189057,-88.196182
42.186513,-88.200645
42.180917,-88.197899
42.178881,-88.192062
41.881656,-87.6297
41.875521,-87.6297
41.87872,-87.636566
41.872073,-87.62661
41.868239,-87.634506
41.86875,-87.624893
41.883065,-87.62352
41.881021,-87.619743
41.879998,-87.620087
41.8915,-87.633476
41.875163,-87.620773
41.879125,-87.62558
41.862763,-87.608757
41.858672,-87.607899
41.865192,-87.615795
41.87005,-87.62043
42.073061,-87.973022
42.317241,-88.187256
42.272546,-88.088379
42.244086,-87.890625
42.044512,-88.28064
39.754977,-86.154785
39.754977,-89.648437
41.043369,-85.12207
43.050074,-89.406738
43.082179,-87.912598
42.7281,-84.572754
39.974226,-83.056641
38.888093,-77.01416
39.923692,-75.168457
40.794318,-73.959961
40.877439,-73.146973
40.611086,-73.740234
40.627764,-73.234863
41.784881,-71.367187
42.371988,-70.993652
35.224587,-80.793457
36.753465,-76.069336
39.263361,-76.530762
25.737127,-80.222168
26.644083,-81.958008
30.50223,-87.275391
29.436309,-98.525391
30.217839,-97.844238
29.742023,-95.361328
31.500409,-97.163086
32.691688,-96.877441
32.691688,-97.404785
35.095754,-106.655273
33.425138,-112.104492
32.873244,-117.114258
33.973545,-118.256836
33.681497,-117.905273
33.622982,-117.734985
33.741828,-118.092041
33.64585,-117.861328
33.700707,-118.015137
33.801189,-118.251343
33.513132,-117.740479
32.777244,-117.235107
32.707939,-117.158203
32.703317,-117.268066
32.610821,-117.075806
34.419726,-119.701538
37.750358,-122.431641
37.50673,-122.387695
37.174817,-121.904297
37.157307,-122.321777
37.271492,-122.033386
37.435238,-122.217407
37.687794,-122.415161
37.542025,-122.299805
37.609506,-122.398682
37.544203,-122.0224
37.422151,-122.13501
37.395971,-122.080078
45.485651,-122.739258
47.719463,-122.255859
47.303913,-122.607422
45.176713,-122.167969
39.566,-104.985352
39.124201,-94.614258
35.454518,-97.426758
38.473482,-90.175781
45.021612,-93.251953
42.417881,-83.056641
41.371141,-81.782227
33.791132,-84.331055
30.252543,-90.439453
37.421248,-122.174835
37.47794,-122.181702
37.510628,-122.254486
37.56943,-122.346497
37.593373,-122.384949
37.620571,-122.489319
36.984249,-122.03064
36.553017,-121.893311
36.654442,-121.772461
36.482381,-121.876831
36.15042,-121.651611
36.274518,-121.838379
37.817717,-119.569702
39.31657,-120.140991
38.933041,-119.992676
39.13785,-119.778442
39.108019,-120.239868
38.586082,-121.503296
38.723354,-121.289062
37.878444,-119.437866
37.782994,-119.470825
37.973771,-119.685059
39.001377,-120.17395
40.709076,-73.948975
40.846346,-73.861084
40.780452,-73.959961
40.778829,-73.958931
40.78372,-73.966012
40.783688,-73.965325
40.783692,-73.965615
40.783675,-73.965741
40.783835,-73.965873
'''
import StringIO
import numpy as np
import re
import matplotlib.pyplot as plt
def lp(l):
return map(lambda m: float(m.group()),re.finditer('[^, \n]+',l))
data=np.array(map(lp,StringIO.StringIO(sdata)))
xmn=np.min(data[:,0])
xmx=np.max(data[:,0])
ymn=np.min(data[:,1])
ymx=np.max(data[:,1])
# area of the point set bounding box
area=(xmx-xmn)*(ymx-ymn)
M_ITER=100 #maximum number of iterations
THRESH=1e-10 # stopping threshold
def em(x):
print '\nSTART EM'
mlst=[]
mu0=np.mean( data , 0 ) # the sample mean of the data - use this as the mean of the low-precision gaussian
# the mean of the high-precision Gaussian - this is what we are looking for
mu=np.random.rand( 2 )*np.array([xmx-xmn,ymx-ymn])+np.array([xmn,ymn])
lam_lo=.001 # precision of the low-precision Gaussian
lam_hi=.1 # precision of the high-precision Gaussian
prz=np.random.rand( 1 ) # probability of choosing the high-precision Gaussian mixture component
for i in xrange(M_ITER):
mlst.append(mu[:])
l_hi=np.log(prz)+np.log(lam_hi)-.5*lam_hi*np.sum((x-mu)**2,1)
#low-precision normal background distribution
l_lo=np.log(1.0-prz)+np.log(lam_lo)-.5*lam_lo*np.sum((x-mu0)**2,1)
#uncomment for the uniform background distribution
#l_lo=np.log(1.0-prz)-np.log(area)
#expectation step
zs=1.0/(1.0+np.exp(l_lo-l_hi))
#compute bound on the likelihood
lh=np.sum(zs*l_hi+(1.0-zs)*l_lo)
print i,lh
#maximization step
mu=np.sum(zs[:,None]*x,0)/np.sum(zs) #mean
lam_hi=np.sum(zs)/np.sum(zs*.5*np.sum((x-mu)**2,1)) #precision
prz=1.0/(1.0+np.sum(1.0-zs)/np.sum(zs)) #mixure component probability
try:
if np.abs((lh-old_lh)/lh)<THRESH:
break
except:
pass
old_lh=lh
mlst.append(mu[:])
return lh,lam_hi,mlst
if __name__=='__main__':
#repeat the EM algorithm a number of times and get the run with the best log likelihood
mx_prm=em(data)
for i in xrange(4):
prm=em(data)
if prm[0]>mx_prm[0]:
mx_prm=prm
print prm[0]
print mx_prm[0]
lh,lam_hi,mlst=mx_prm
mu=mlst[-1]
print 'best loglikelihood:', lh
#print 'final precision value:', lam_hi
print 'point of interest:', mu
plt.plot(data[:,0],data[:,1],'.b')
for m in mlst:
plt.plot(m[0],m[1],'xr')
plt.show()