I have a motion capture file that has some information which looks like:
I need the file to look like this:
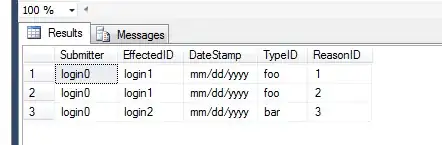
The difference is that i dont need any of the top parts, just starting at row 31 column b. The on line 31, there is the keywords like LFHD and under it is xyz positions. My code works with the modified version by reading the csv and getting a dictionary for each line:
filename = args
jointCSVs=[]
if filename != None:
print "Trying to get file"
joint_file = open(str(filename),"rb")
reader = csv.DictReader(joint_file)
print "Got File"
for data in reader:
jointCSVs.append(data)
return jointCSVs
I cant find any good information on how to do more complex things with python and csv's, especially since with my code, only the first block is read in and it ends when there is the whitespace. I even tried this code that i found but it wouldnt open the first csv file, it just crashes: pyqt - populating QTableWidget with csv data
It takes too long to modify by hand, and i have lots of these files. Later I plan on making some more gui stuff that can edit the files and modify them or select parts which would be useful for many people dealing with mocap data. I couldnt find any libraries for complex data manipulation or easy methods for specifying rows and columns to remove from a file. Does this exist or can someone explain how to do this?
Thanks!