I am using Ubuntu 12.04, Python 2.7 & PocketSphinx.
I made a custom dictionary, language model using online LM tool. Using pocketsphinx_continous to decode the spoken voice gives me 100% accuracy.
But using PyAudioto record sound in Python recognises the text but adds 'A' and 'AND' with the main context as shown in the images below
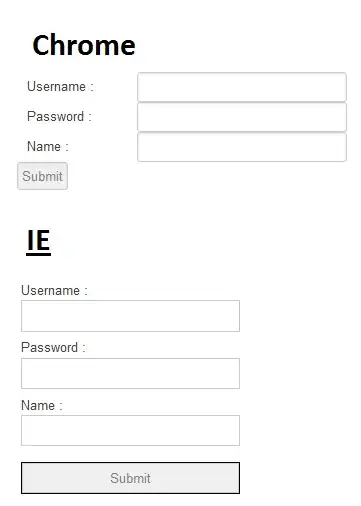
 How to cure it?
How to cure it?