I want to perform a k means clustering analysis on a set of 10 data points that each have an array of 4 numeric values associated with them. I'm using the Pearson correlation coefficient as the distance metric. I did the first two steps of the k means clustering algorithm which were:
1) Select a set of initial centres of k clusters. [I selected two initial centres at random]
2) Assign each object to the cluster with the closest centre. [I used the Pearson correlation coefficient as the distance metric -- See below]
Now I need help understanding the 3rd step in the algorithm:
3) Compute the new centres of the clusters:
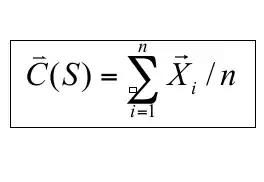
where X, in this case is a 4 dimensional vector and n is the number of data points in the cluster.
How would I go about calculating C(S) for say the following data?
# Cluster 1
A 10 15 20 25 # randomly chosen centre
B 21 33 21 23
C 43 14 23 23
D 37 45 43 49
E 40 43 32 32
# Cluster 2
F 100 102 143 212 #random chosen centre
G 303 213 212 302
H 102 329 203 212
I 32 201 430 48
J 60 99 87 34
The last step of the k means algorithm is to repeat step 2 and 3 until no object changes cluster which is simple enough.
I need help with step 3. Computing the new centres of the clusters. If someone could go through and explain how to compute the new centre of just one of the clusters, that would help me immensely.