Updated: see below
I have figured out how to get the Key Name field filled in for my dataset so that I have now reduced the write ops by 2 (down from 8). But I still have this extra empty column "ID". I have tried various configurations of the bulkloader.py, but I am unable to populate that column and hopefully reduce my write ops down further...
Here's what I have:
python_preamble:
- import: base64
- import: re
- import: google.appengine.ext.bulkload.transform
- import: google.appengine.ext.bulkload.bulkloader_wizard
- import: google.appengine.ext.db
- import: google.appengine.api.datastore
- import: google.appengine.api.users
transformers:
- kind: Word
connector: csv
property_map:
- property: __key__
external_name: word
export_transform: transform.key_id_or_name_as_string
- property: ID
external_name: ID
# How to configure this one to use up that silly empty column called "ID"?
- property: otherlangs
external_name: otherlangs
Here is the header of my csv file and some sample rows:
$ head allting.csv
ID,word,otherlangs
100,a,it|uno|
200,aaltos,fi|aaltojen|
300,aardvark,is|jarðsvín|nl|aardvarken|
Update: Okay, well, I found out how to populate the "ID" column at the expense of the "Key Name" column...
I changed my bulkload.py to look like this:
transformers:
- kind: Word
connector: csv
connector_options:
encoding: utf-8
columns: from_header
property_map:
- property: __key__
external_name: id
export_transform: transform.key_id_or_name_as_string
import_transform: transform.create_foreign_key('id', key_is_id=True)
- property: word·
external_name: word·
- property: otherlangs·
external_name: otherlangs·
The csv file looks like this:
id,word,otherlangs
100,a,it|uno|
200,aaltos,fi|aaltojen|
...
And the output in the Datastore Viewer looks like this now:
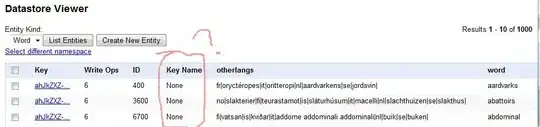
Still wondering if there's any way to populate the ID and the "Key Name" column and get the write ops down to 4?