I have an array of shorts where I want to grab half of the values and put them in a new array that is half the size. I want to grab particular values in this sort of pattern, where each block is 128 bits (8 shorts). This is the only pattern I will use, it doesn't need to be "any generic pattern"!
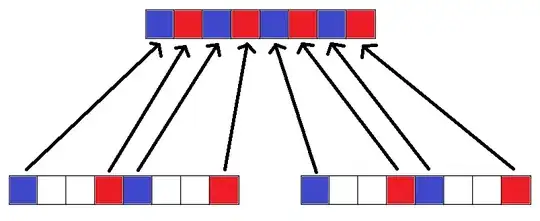
The values in white are discarded. My array sizes will always be a power of 2. Here's the vague idea of it, unvectorized:
unsigned short size = 1 << 8;
unsigned short* data = new unsigned short[size];
...
unsigned short* newdata = new unsigned short[size >>= 1];
unsigned int* uintdata = (unsigned int*) data;
unsigned int* uintnewdata = (unsigned int*) newdata;
for (unsigned short uintsize = size >> 1, i = 0; i < uintsize; ++i)
{
uintnewdata[i] = (uintdata[i * 2] & 0xFFFF0000) | (uintdata[(i * 2) + 1] & 0x0000FFFF);
}
I started out with something like this:
static const __m128i startmask128 = _mm_setr_epi32(0xFFFF0000, 0x00000000, 0xFFFF0000, 0x00000000);
static const __m128i endmask128 = _mm_setr_epi32(0x00000000, 0x0000FFFF, 0x00000000, 0x0000FFFF);
__m128i* data128 = (__m128i*) data;
__m128i* newdata128 = (__m128i*) newdata;
and I can iteratively perform _mm_and_si128 with the masks to get the values I'm looking for, combine with _mm_or_si128, and put the results in newdata128[i]. However, I don't know how to "compress" things together and remove the values in white. And it seems if I could do that, I wouldn't need the masks at all.

How can that be done?
Anyway, eventually I will also want to do the opposite of this operation as well, and create a new array of twice the size and spread out current values within it.

I will also have new values to insert in the white blocks, which I would have to compute with each pair of shorts in the original data, iteratively. This computation would not be vectorizable, but the insertion of the resulting values should be. How could I "spread out" my current values into the new array, and what would be the best way to insert my computed values? Should I compute them all for each 128-bit iteration and put them into their own temp block (64 bit? 128 bit?), then do something to insert in bulk? Or should they be emplaced directly into my target __m128i, as it seems the cost should be equivalent to putting in a temp? If so, how could that be done without messing up my other values?
I would prefer to use SSE2 operations at most for this.