Here is an explanation of how the algorithm you have found will handle your example problem.
The problem is to find the shortest path between node one and node four with the extra condition that the accumulated cost along the way should not be more than 7.
The solution we want to find is to first go from node one to node node two, a distance of 190 and at a cost of 4. And then go from node two to node four using the path of distance 195 and cost 3. In total the path has a distance of 385and a cost of 7.
Step 1
So how does the algorithm find this? The first step is to set up the matrix minArray(i,j) just like you have done. The element (i,j) of the array holds the distance you must travel to get to node j with exactly i money remaining.
Starting out there are no visited elements and since we are starting at node one with 7 "monies" the top left element is set to zero. The empty spaces in the table above correspond to values that are set to infinity in the array.
Step 2
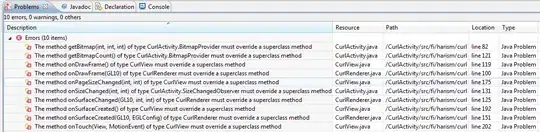
Next, we find the lowest value of the array, this is the zero at position (remaining money, node) = (7,1). This element is set to visited (the state of an element is kept track of using a matrix visitedArray of the same size as minArray) which means that we have selected node one. Now all nodes that connect to node one are updated with values by traversing the corresponding edges.
Here minArray(6,3) = 191 which means that we have gone a distance of 191 to get to node three and the money we have left is 6 since we have payed a cost of 1 to get there. In the same way minArray(3,2) is set to 190. The red square marks that element (7,1) is visited.
Step 3
Now we again find the lowest unvisited element (which is minArray(3,2) = 190), set it to visited and update all elements that connect to it. This means that the distance is accumulated and the remaining money is calculated by subtracting the cost from the current value.
Note that it is too expensive to go back to node one from node two.
Step 4
The next step, selecting minArray(6,3) = 191 looks like this.

Step 5
Three steps later the array looks like this. Here the two elements that equal 382 and the one that equals 383 have been selected. Note that the value of an element is only updated if it is an improvement of (i.e. lower than) the current value.
Step 6
The array continues to fill up until all elements are either visited or still have infinite value.
Final step
The final step is to find the total distance by finding the lowest value of column four. We can see that the minimal value, minArray(0,4) = 385 corresponds to the correct solution.
Note: If all values of column four would have been infinite, it would mean that there is no valid solution. The algorithm also specifies that if there are multiple values of equal and minimal distance in column four, the cheapest one is selected.