I have an XML file that can be as big as 1GB. I am using XOM to avoid OutOfMemory Exceptions.
I need to canonicalize the entire document, but the canonicalization takes a long time, even for a 1.5 MB file.
Here is what I have done:
I have this sample XML file and I increase the size of the document by replicating the Item node.
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<Packet id="some" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<Head>
<PacketId>a34567890</PacketId>
<PacketHeadItem1>12345</PacketHeadItem1>
<PacketHeadItem2>1</PacketHeadItem2>
<PacketHeadItem3>18</PacketHeadItem3>
<PacketHeadItem4/>
<PacketHeadItem5>12082011111408</PacketHeadItem5>
<PacketHeadItem6>1</PacketHeadItem6>
</Head>
<List id="list">
<Item>
<Item1>item1</Item1>
<Item2>item2</Item2>
<Item3>item3</Item3>
<Item4>item4</Item4>
<Item5>item5</Item5>
<Item6>item6</Item6>
<Item7>item7</Item7>
</Item>
</List>
</Packet>
The code I am using for canonicalization is as follows:
private static void canonXOM() throws Exception {
String file = "D:\\PACKET.xml";
FileInputStream xmlFile = new FileInputStream(file);
Builder builder = new Builder(false);
Document doc = builder.build(xmlFile);
FileOutputStream fos = new FileOutputStream("D:\\canon.xml");
Canonicalizer outputter = new Canonicalizer(fos);
System.out.println("Query");
Nodes nodes = doc.getRootElement().query("./descendant-or-self::node()|./@*");
System.out.println("Canon");
outputter.write(nodes);
fos.close();
}
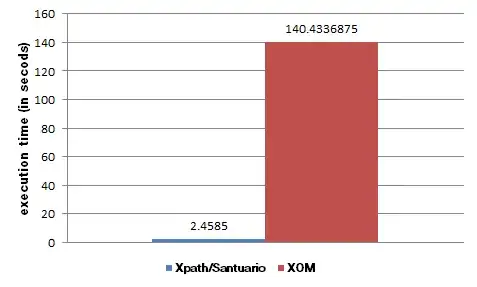
Even though this code works well for small files, the canonicalization part takes about 7 minutes for a 1.5mb file on my development environment (4gb ram, 64bit, eclipse, windows)
Any pointers to the cause of this delay is highly appreciated.
PS. I need to canonicalize segments from a whole XML document, as well as the whole document itself. So, using the document itself as the argument does not work for me.
Best