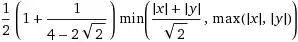Ok, sorry but this isn't in c and its not using opencv, however I'm sure labelling must be possible in opencv, just I haven't used it yet... so this might help... Basically the idea is:
- Find, and label all separate blobs in the image
- Remove all blobs that fall outside certain constraints (size, shape)
Here I implement this in python using scipy, but just for size (not shape, although this is easy and would get rid of the long thin lines in first image below). For this to work we must know an acceptable range of sizes for the letters - however you could determine this after labelling by looking at average blob size.. You may still get letter sized false positives - but these could possibly be removed by observing that they fall outside a certain area of concentrated blobs (as text is spacially regular)... Also minimum sentence length could be a powerful constraint.
Anyhow, code:
import scipy
from scipy import ndimage
im = scipy.misc.imread('learning2.png',flatten=1)
#threshold image, so its binary, then invert (`label` needs this):
im[im>100]=255
im[im<=100]=0
im = 255 - im
#label the image:
blobs, number_of_blobs = ndimage.label(im)
#remove all labelled blobs that are outside of our size constraints:
for i in xrange(number_of_blobs):
if blobs[blobs==i].size < 40 or blobs[blobs==i].size>150:
im[blobs==i] = 0
scipy.misc.imsave('out.png', im)
results: