I need some suggestions from the database design experts here.
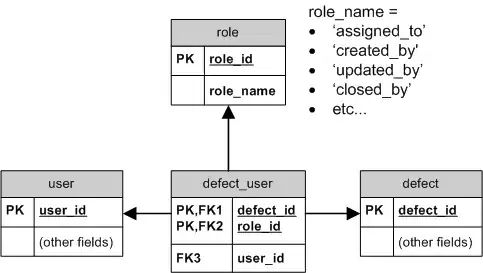
I have around six foreign keys into a single table (defect) which all point to primary key in user table. It is like:
defect (.....,assigned_to,created_by,updated_by,closed_by...)If I want to get information about the defect I can make six joins. Do we have any better way to do it?
Another one is I have a
statestable which can store one of the user-defined set of values. I have defect table and task table and I want both of these tables to share the common state table (New, In Progress etc.). So I created:task (.....,state_id,imp_id,.....)defect(.....,state_id,imp_id,...)state(state_id,state_name,...)importance(imp_id,imp_name,...)
There are many such common attributes along with state like importance(normal, urgent etc), priority etc. And for all of them I want to use same table. I am keeping one flag in each of the tables to differentiate task and defect. What is the best solution in such a case?
If somebody is using this application in health domain, they would like to assign different types, states, importances for their defect or tasks. Moreover when a user selects any project I want to display all the types,states etc under configuration parameters section.