I have a VPS that runs a Java server, a redis server and a PostgreSQL server.
Everything is running well but last night my server "crashed" at 3:15:50 AM. At least that's what I thought.
I looked at my server log and I saw several exceptions caused by the database and then nothing more.
I looked at redis log :
[733 | signal handler] (1429751751) Received SIGTERM scheduling shutdown...
[733] 23 Apr 03:15:51.977 # User requested shutdown...
[733] 23 Apr 03:15:51.977 * Calling fsync() on the AOF file.
[733] 23 Apr 03:15:51.977 * Saving the final RDB snapshot before exiting.
[733] 23 Apr 03:15:51.996 * DB saved on disk
[733] 23 Apr 03:15:51.996 * Removing the pid file.
[733] 23 Apr 03:15:51.996 # Redis is now ready to exit, bye bye...
Ok, a SIGTERM.
I also looked at PostgreSQL's logs :
2015-04-23 03:15:50 CEST LOG: received fast shutdown request
2015-04-23 03:15:50 CEST LOG: aborting any active transactions
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST FATAL: terminating connection due to administrator command
2015-04-23 03:15:50 CEST LOG: autovacuum launcher shutting down
2015-04-23 03:15:50 CEST LOG: shutting down
2015-04-23 03:15:50 CEST LOG: database system is shut down
Mmmh. A shutdown request? A SIGTERM signal in other words, right?
I also looked at several system logs, like daemon.log and syslog :
Apr 23 03:15:47 vps89164 xinetd[12314]: Exiting...
Apr 23 03:15:48 vps89164 named[604]: received control channel command 'stop -p'
Apr 23 03:15:48 vps89164 named[604]: shutting down: flushing changes
Apr 23 03:15:48 vps89164 named[604]: stopping command channel on 127.0.0.1#953
Apr 23 03:15:48 vps89164 named[604]: stopping command channel on ::1#953
Apr 23 03:15:48 vps89164 named[604]: no longer listening on ::#53
Apr 23 03:15:48 vps89164 named[604]: no longer listening on 127.0.0.1#53
Apr 23 03:15:48 vps89164 named[604]: no longer listening on 127.0.0.2#53
Apr 23 03:15:48 vps89164 named[604]: no longer listening on 37.59.110.223#53
Apr 23 03:15:48 vps89164 named[604]: exiting
And I looked at auth.log :
sshd[435]: Received signal 15; terminating.
saslauthd[758]: server_exit : master exited: 758
Signal 15. SIGTERM in other words.
So, tell me if I'm wrong but it seems that there was no crash at 3:15:50 AM but just a VPS restart right?
But why? Why would a restart appear? I didn't do anything (i was sleeping). How can I know what happened?
I look at my RAM usage (that was often an issue), but it was not even at 100% use (and CPU was only at 3% use).
Here is a capture of my RAM usage for the last 24 hours :
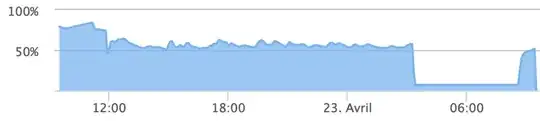
When I look at auth.log I can also see a lot of connection tries :
Apr 23 03:15:43 vps89164 sshd[23481]: pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=mail.setac.com.py user=root
Apr 23 03:15:44 vps89164 sshd[23479]: Failed password for root from 58.218.199.195 port 49241 ssh2
Apr 23 03:15:44 vps89164 sshd[23481]: Failed password for root from 181.40.125.54 port 46047 ssh2
Apr 23 03:15:45 vps89164 sshd[23481]: Received disconnect from 181.40.125.54: 11: Bye Bye [preauth]
Apr 23 03:15:45 vps89164 sshd[23484]: error: Could not load host key: /etc/ssh/ssh_host_ecdsa_key
Apr 23 03:15:46 vps89164 sshd[23479]: Failed password for root from 58.218.199.195 port 49241 ssh2
Apr 23 03:15:46 vps89164 sshd[23479]: Received disconnect from 58.218.199.195: 11: [preauth]
Apr 23 03:15:46 vps89164 sshd[23479]: PAM 2 more authentication failures; logname= uid=0 euid=0 tty=ssh ruser= rhost=58.218.199.195 user=root
This is only a sample, there are thousands of lines like these ones However no try seem to succeed so I don't think someone accessed the server and restarted it (and why only restarting a server when you have a root access to it and can do whatever you want?)
Now I'm lost, this is not the first time this is happening. This is annoying and I can't figure out why this is happening and how. I don't know how to search know and I'm requesting your help :(
By the way, I'm using an Ubuntu server