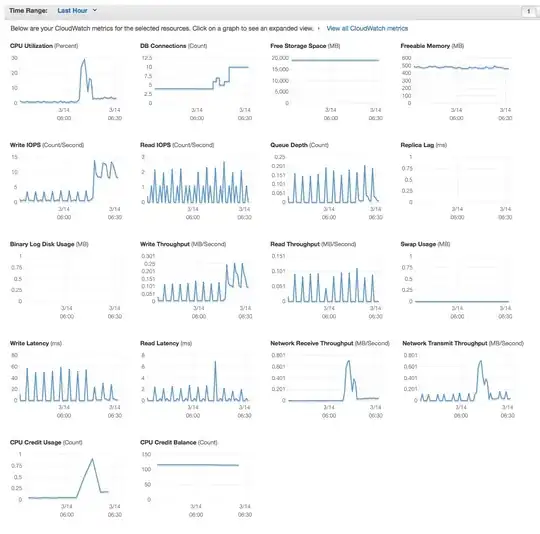
I've just started trying out AWS. I have a Postgres micro instance on RDS and I'm running a crawler on a c4.large. When I have just one spider (one thread), I get about 10 write IOPS. but if two spiders (2 threads) were deployed, I get about just 7 write IOPS. If I understand correctly, since I've allocated 20gb, the maximum IOPS should be 60IOPS in total. I've attached the monitoring below.
When only one spider was deployed:
When a second spider was deployed alongside:
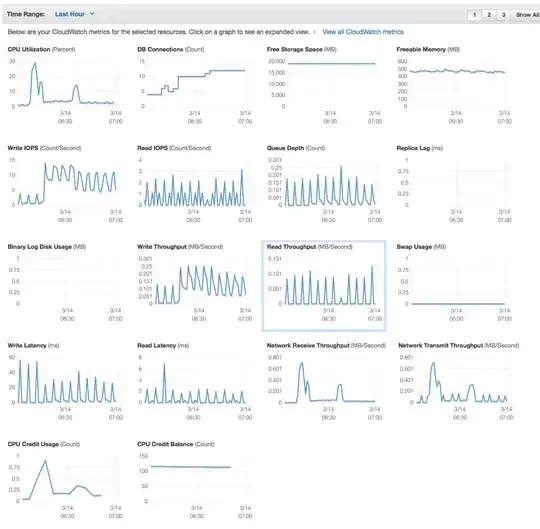
Note the drop from an average 10 write IOPS to an average 7 write IOPS.
Any help will be much appreciated.