I'm running ESXi 5.5 (Build 2068190) on a Dell PowerEdge R220 server with the Intel E3-1220v3 CPU. It also has 16 GB of RAM installed and 2 x 1TB SATA disks running as RAID1 using a Dell PERC H310 controller.
Here's the problem. A few hours ago I noticed one of the guests causing major cpu spikes on the server. Spikes that were so intense the entire host freeze which also affected all other guests on the host. The guest in question only has 1 core assigned to it and running Debian 7 x64.
Have a look at the attached image below.
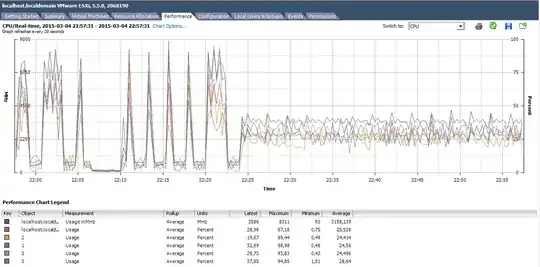
The lag spikes on the left side of the chart occured about every other minute and lasted for about a full minute. The longer stop between 22:05 and 22:10 was when I shut the guest down to confirm that it was causing the cpu spikes. What happens at 22:25 is that I limited the guest CPU to 2 GHz. This stopped the spikes from happening, but now the entire server runs very slowly. When clicking something in vSphere client it takes about 5 seconds to bring up a new window.
The only thing I did before this happened was to change the name of a vSwitch, I don't know if that's what really caused it though. I also made some changes on a different guest acting as a gateway for the other guests running vyos but I fail to see how that can cause it.
And no, I don't have access to the guest at hand because it belongs to a customer. However I know that it only runs apache2, mysql and mailman.
My questions are:
a) Anyone know what is causing this or what I can do to find out what is causing it?
b) I didn't think one guest would be able to affect the entire host and other guests in this way, is this how it is supposed to be?
Thanks in advance, let me know if you need more info.
EDIT: After digging we found out the guest VPS had been compromised and was used as a FTP dump by hackers, which explains the intense traffic (350 GB in a couple of hours). However, it doesn't explain why it affected the host or other guests. Do I need to limit CPU performance by clockrate rather than just number of cores in order to avoid having one guest affect others? Or could it be something different like the vSwitches (and in turn ESXi) were somehow overloaded with work?
EDIT 2: Turns out it wasn't an FTP dump rather they made the server take part in a ddos attack of some sort. Our ISP called us later saying the amount of traffic had affected their other services / customers so I'm guessing it was quite a bit of traffic.