I have a very confusing issue which I can't seem to resolve.
I followed a guide by Loic Dachary on installing Openstack Folsom on Wheezy, and deployed it on two hosts: a cluster node, and my workstation.
On these two hosts I'm running a benchmarking application that communicated from one host to the other in the following fashion:
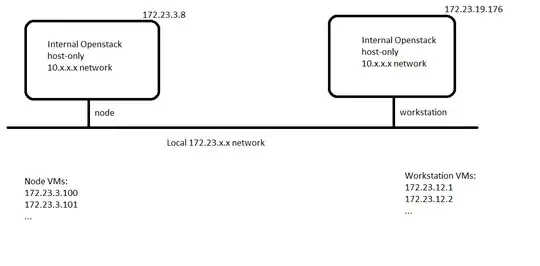
The following are the routing tables for the node host, the workstation, and the internal VMs:
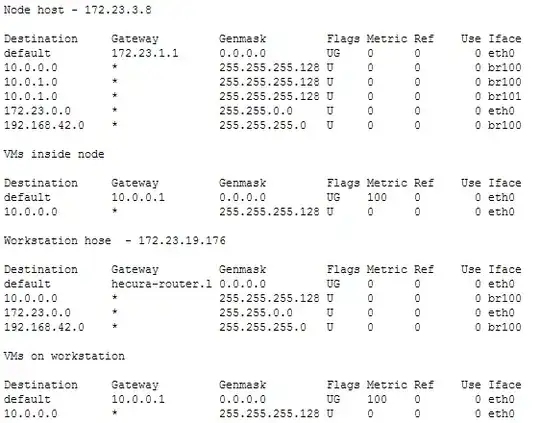
(Note: the 10.0.1.0 entry was for an additional network interface. It ended up being unneeded and is not up on any of the VMs. Hence, it has no impact since nothing is being routed to destination 10.0.1.x)
Now, my issue is the following:
The benchmarking application starts an RMI call from one of the VMs on the workstation, (say 10.0.0.2) to one of the VMs on the node (say, 172.23.3.100).
It is my understanding that the following should occur:
The VM sees desination 172.23.x.x network route and goes through the default route 10.0.0.1 (the workstation compute host)
The nova network service sees that 10.0.0.2 is mapped to some IP (say, 172.23.12.1) on the local network. So it changes the source IP to that.
The workstation host sees destination 172.23.x.x and routes through 172.23.1.1 to 172.23.3.8.
Nova network sees the IP and since the mapping say, 172.23.3.100 -> 10.0.0.7 exists, it changes destination to 10.0.0.7.
VM on node with internal IP 10.0.0.7 gets the the request from workstation VM. (@ 172.23.12.1).
This works fine. The actual request gets sent. However, there is something wrong with the reply.
Here's the log of my application run just after the request is sent:
RemoteException was: java.rmi.ServerException: RemoteException occurred in server thread; nested exception is:
-> java.rmi.ConnectIOException: Exception creating connection to: 10.0.0.7; nested exception is:
-> java.net.NoRouteToHostException: No route to host
So it must be the case that the node VM replied with it's source being 10.0.0.7. In other words, the nova network service never changed the source IP of the node VM to its routable 172.23.x.x address!
How is this possible? Both VM's can ping themselves (node->workstation, workstation->node), and I don't see anything wrong with the routing tables.
The only odd factor I can see is the following traceroute information:
Workstation VM -> Node
root@client-01:~# traceroute 172.23.3.8
traceroute to 172.23.3.8 (172.23.3.8), 30 hops max, 60 byte packets
1 10.0.0.1 (10.0.0.1) 0.406 ms 0.399 ms 0.390 ms
2 172.23.3.8 (172.23.3.8) 0.381 ms 0.378 ms 0.422 ms
root@client-01:~#
Node VM -> Workstation
root@idleserver-vm:~# traceroute 172.23.19.176
traceroute to 172.23.19.176 (172.23.19.176), 30 hops max, 60 byte packets
1 10.0.0.1 (10.0.0.1) 0.741 ms 0.676 ms 0.657 ms
2 172.23.19.176 (172.23.19.176) 0.643 ms 0.638 ms 0.626 ms
root@idleserver-vm:~#
These work fine. However...
Node VM -> Workstation VM
root@idleserver-vm:~# traceroute client01
traceroute to client01 (172.23.12.1), 30 hops max, 60 byte packets
1 10.0.0.1 (10.0.0.1) 0.808 ms 0.739 ms 0.721 ms
2 client01 (172.23.12.1) 0.707 ms 0.702 ms 0.688 ms
3 * * *
4 * * *
5 * * *
Workstation VM -> Node VM
root@client-01:~# traceroute idleserver
traceroute to idleserver (172.23.3.105), 30 hops max, 60 byte packets
1 10.0.0.1 (10.0.0.1) 0.296 ms 0.239 ms 0.224 ms
2 idleserver (172.23.3.105) 0.213 ms 0.200 ms 0.189 ms
3 * * *
4 * * *
5 * * *
These do not seem to get a reply from the end VM, for likely the same reason. Pings however, work just fine:
root@client-01:~# ping idleserver
PING idleserver (172.23.3.105) 56(84) bytes of data.
64 bytes from idleserver (172.23.3.105): icmp_req=1 ttl=62 time=1.02 ms
64 bytes from idleserver (172.23.3.105): icmp_req=2 ttl=62 time=0.914 ms
root@idleserver-vm:~# ping client01
PING client01 (172.23.12.1) 56(84) bytes of data.
64 bytes from client01 (172.23.12.1): icmp_req=1 ttl=62 time=0.675 ms
64 bytes from client01 (172.23.12.1): icmp_req=2 ttl=62 time=0.875 ms
What in the world could be going on here?
EDIT: Having spoken with the network administrator, he helped me troubleshoot the issue a bit. It seems that nova-network is not correctly letting UDP packets pass through, hence traceroute is failing. Using the following:
root@idleserver-vm:~# traceroute -T client01
traceroute to client01 (172.23.12.1), 30 hops max, 60 byte packets
1 10.0.0.1 (10.0.0.1) 0.766 ms 0.756 ms 0.748 ms
2 client01 (172.23.12.1) 0.737 ms 0.728 ms 0.720 ms
3 client01 (172.23.12.1) 1.046 ms 1.046 ms 1.034 ms
I do have UDP ports open on both the receiving VM and the requesting VM (I also tried specific ports I know for certain are open), so I don't think it could possibly be a port issue.
(PS. I posted this on ask.Openstack as well in hopes of getting more views and a quicker resolution)