As discussed in a previous question, we have 6 OWC Mercury Extreme SATA SSD drives installed in our HP Proliant DL360 G7 server (using a P410i RAID controller). They work great, and are very fast. However, I'm aware that SSD drives unfortunately don't last forever, and the HP ACU utility, not surprisingly, won't monitor the health of any of the drives:
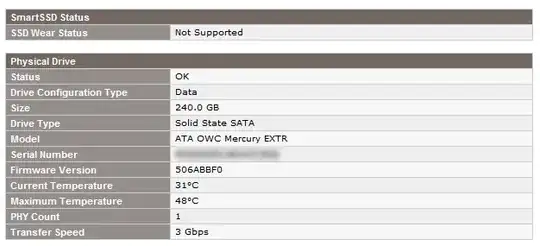
Does anyone know of any Windows (Server 2008R2) software or utilities that will allow monitoring of the health of each individual drive in the array, so that we can proactively pick up on any potential issues?