This vCenter server was just upgraded to 5.1 update 1. I'm going through hosts and bringing firmware up to date, then upgrading them from various versions of 5.0 to 5.1u1.
vCenter 5.1u1 seems to have an interesting new behavior: it's removing hosts from maintenance mode when they reconnect after being disconnected -- but very inconsistently, I've seen it maybe 4 or 5 times on ~25-30 host reboots. I've only seen it happen on 5.0 hosts that have not yet been upgraded to 5.1.

In the image, I placed the host in maint mode and rebooted it into the HP SPP DVD's automatic update mode. After its usual ~40 minute update process, the host came back online.. and 7 seconds before even logging that the host had reconnected, vCenter had sent the host a task to exit maintenance mode.
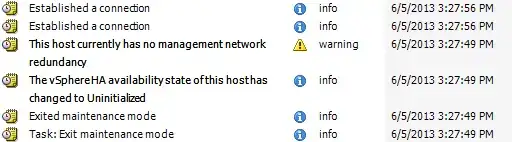
In my understanding, the only time vCenter should drop a host out of maintenance mode is when vCenter put it into maintenance mode itself (such as a VUM upgrade task).
Why would this vCenter be unilaterally exiting a host from user-initiated maintenance mode?
Edit, additional info:
I ran the firmware upgrades on 5 more hosts, all at the same time. Two of them exited maint mode after reconnecting, three did not. The common factor of those exiting maint mode seems to be how long they were offline; the two that took a few tries to boot to the virtual media are the two that got knocked out of maint mode.
- esx31 (image above): 45 minutes unresponsive
- esx19 (exited maint): 87 minutes unresponsive
- esx24 (stayed in maint): 32 minutes unresponsive
- esx29 (stayed in maint): 39 minutes unresponsive
- esx32 (stayed in maint): 30 minutes unresponsive
- esx34 (exited maint): 70 minutes unresponsive
Edit: The disconnect time idea seems to have been a red herring, as it's not happening consistently.
Additionally, in the vpxd.log the exit maint mode task initiation seems to always immediately follow this vim.EnvironmentBrowser.queryProvisioningPolicy SOAP call. Here's the lines, slightly trimmed for clarity:
15:27:49.535 [info 'vpxdvpxdVmomi'] [ClientAdapterBase::InvokeOnSoap] Invoke done (esx31, vim.EnvironmentBrowser.queryProvisioningPolicy)
15:27:49.560 [info 'commonvpxLro'] [VpxLRO] -- BEGIN task -- esx31 -- HostSystem.exitMaintenanceMode --
Note that on the nodes that don't get the exit task, the vim.EnvironmentBrowser.queryProvisioningPolicy event still occurs. I'm not seeing any other differences in events before or after this in the reconnect process, aside from the extra events caused by exiting maintenance mode.
Given the log's mention of provisioning policies, looking for autodeploy-related maintenance mode issues turns up complaints about similar behavior (though I'm not using autodeploy at all).