We have a Windows 2003 R2 Enterprise 64-bit server running a custom workload suffering from an odd performance problem. The pared-down version below suffers from a smaller hump, but it's qualitatively the same.
We've reduced it down to a simple trivial app doing nothing more than:
- listening on a socket
- joining a multicast group
- listening for packets coming in on that group
- reading and discarding the packets
The test application itself is a slightly modified version of the Boost ASIO multicast receiver example so there's not really much that ought to be going wrong. Actual code(!) below…
Every so often while running this program under load, the CPU for this process will ramp up with all of the processing happening in kernel code:
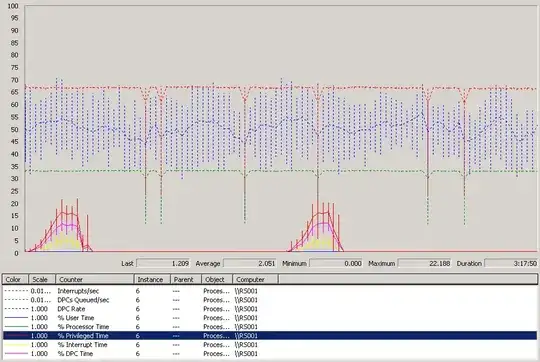 (only CPU 6 is shown here. For the duration of this test (3h17m) all other processors are idle)
(only CPU 6 is shown here. For the duration of this test (3h17m) all other processors are idle)
As you can see from the graph, when the load spikes hit all of the processing time is happening in kernel code. The time spent is mostly spent in Deferred Procedure Calls (max 16.8%) and handling Interrupts (max 8.5%). It looks like there's some sort of deferred cleanup happening, but we have no idea what it could be.
As far as we can tell it's happening on W2K3E-64 only.
It is happening on different hardware (HS21, HS22, HS22V, HP DL380).
Running the test application on Windows 2008 demonstrates the problem to a much smaller extent (more often but smaller humps).
How can we fix this or where should we look next?
Actual code from the example:
void handle_receive_from(const boost::system::error_code& error,
size_t bytes_recvd)
{
if (!error)
{
++m_receivedPackets;
m_receivedBytes += bytes_recvd;
m_last64TotalBytes += bytes_recvd;
if ( ( m_receivedPackets & 0x3F ) == 0 )
{
printf( "Received %u bytes in %u packets. The average size of the last 64 packets was %u bytes, and the last byte received was %x.\n",
m_receivedBytes, m_receivedPackets, m_last64TotalBytes / 64, m_buffer[ bytes_recvd - 1 ] );
m_last64TotalBytes = 0;
}
m_socket.async_receive_from(
boost::asio::buffer(m_buffer, max_length), m_senderEndpoint,
boost::bind(&receiver::handle_receive_from, this,
boost::asio::placeholders::error,
boost::asio::placeholders::bytes_transferred));
}
else
{
std::cerr << "An error occurred when performing an asyncronous read." << std::endl;
m_socket.get_io_service().stop();
}
}