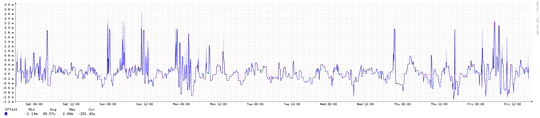
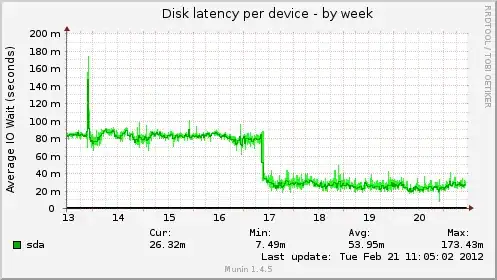
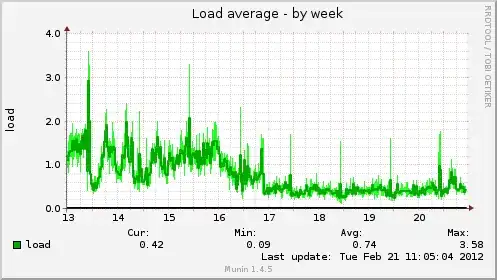
A few days ago I noticed a disk I/O wait and disk activity drop (which was great). Then I also notice that my cache was full(*) and fragmented. Then I flushed cache. After that, disk latency and disk activity jumped to the previous level (which was bad).
IOtop shows that [jbd2/sda2-8] and [flush-8:00] are always on top of disk usage. This is a Dell R210, hardware RAID 1 (H200) with a lot of free memory (16 GB in total, of which about 8 GB are buffer/cache).
(*) The cache is APC opcode cache for PHP, which reduces disk access for PHP script execution. Cache was full and fragmented because it included files from development instance. When I noticed that, I filtered them out.
The question is: why disk I/O increases when theorically it should decrease? Below are some graphs from munin. Cache was full from Feb 6 to 8.
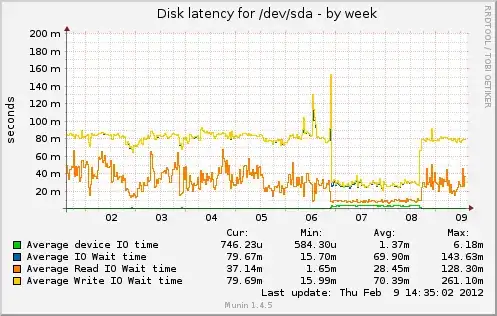
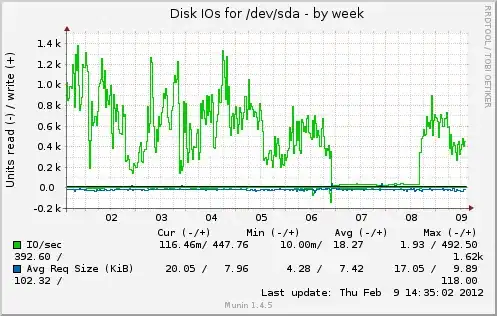
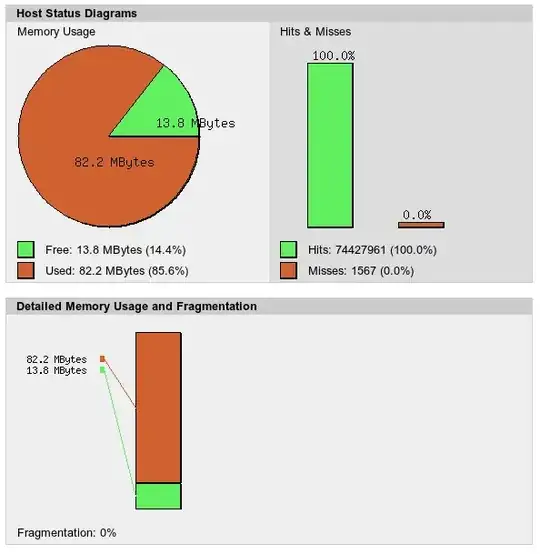
Change after I commented out apc.mmap_file_mask as told by @cyberx86
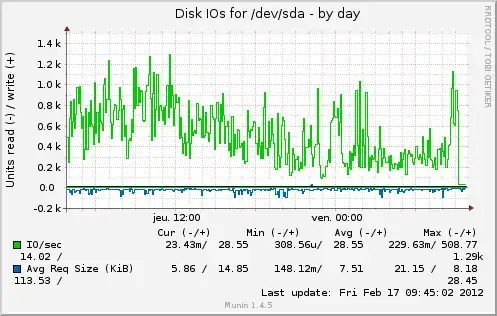
And after a few days https://serverfault.com/a/362152/88934