I don't think your disk is the issue. First nginx's ncache uses a disk store for cache. So, disk speed is going to be one potential cause of issues depending on how hot/cold your dataset is, however, I see no reason that you couldn't serve 100mb/sec with the hardware you've mentioned - especially if you're using nginx.
First thing I would guess is your # of worker processes was low, your worker_connections were probably way too low, and you probably didn't have your open_file_cache set high enough. However, none of those settings would cause a high IO Wait nor a spike like that. You say that you are serving <50k images and it looks like 1/4 of your set could easily be buffered by the OS. Nginx is surely not configured optimally.
Varnish handles the problem in a slightly different way using RAM rather than disk for its cache.
Much depends on your dataset, but, based on the data you've given, I don't see any reason for disk IO to have spiked like that. Did you check dmesg and the logs to see if one of your drives encountered some IO errors at the time? The only other thing I can think that might have caused that spike was exceeding nginx's filecache which would have caused it to have to go into a FIFO mode opening new files.
Make sure your filesystem is mounted with noatime which should cut a considerable amount of writeops off your workload.
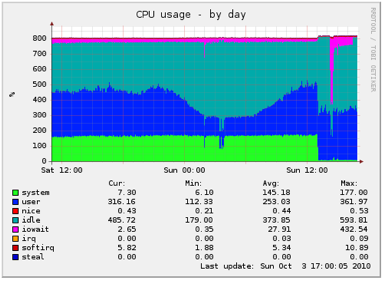
As an example of a machine that regularly handles 800mb/sec:
# uptime
11:32:27 up 11 days, 16:31, 1 user, load average: 0.43, 0.85, 0.82
# free
total used free shared buffers cached
Mem: 8180796 7127000 1053796 0 1152 2397336
-/+ buffers/cache: 4728512 3452284
Swap: 8297568 237940 8059628
Quadcore Xeon:
Intel(R) Xeon(R) CPU X3430 @ 2.40GHz
$ ./bw.pl xxx.xxx 2010-09-01 2010-09-30
bw: 174042.60gb
average 543mb/sec, peaks at 810mb/sec
=== START OF INFORMATION SECTION === Model Family: Seagate Barracuda
7200.12 family Device Model: ST3500418AS Serial Number: 6VM89L1N
Firmware Version: CC38 User Capacity:
500,107,862,016 bytes
Linux 2.6.36-rc5 (xxxxxx) 10/04/2010 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
4.33 0.00 2.40 5.94 0.00 87.33
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 109.61 19020.67 337.28 19047438731 337754190
avg-cpu: %user %nice %system %iowait %steal %idle
8.09 0.00 3.40 10.26 0.00 78.25
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 138.52 21199.60 490.02 106210 2455
avg-cpu: %user %nice %system %iowait %steal %idle
3.74 0.00 3.25 9.01 0.00 84.00
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 125.00 21691.20 139.20 108456 696
avg-cpu: %user %nice %system %iowait %steal %idle
4.75 0.00 3.12 14.02 0.00 78.11
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 154.69 19532.14 261.28 97856 1309
avg-cpu: %user %nice %system %iowait %steal %idle
6.81 0.00 3.36 9.48 0.00 80.36
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 112.80 17635.20 309.00 88176 1545
MRTG:
https://i.stack.imgur.com/CRqPi.png
Dataset:
# du -sh ads
211.0G ads
# ls|wc -l
679075
{kind=link}
{kind=link}