I have 2 physical disks in linux RAID1, I am not sure what happened, I think someone who should not have been in the system partitioned the md0 by mistake while the system was running while trying to add a new disk. Regardless, on reboot, it went to grub. I have spent days trying to fix this with systemrescueCD, and stopped the array which showed "UU" before I stopped it, so it should be good, but I am having an issue with re-assembling it and getting it back to normal operation. I am not sure what to do. It shows FAT32 filesystem, but also ext2, and shows backup superblocks, but also says no superblock exists. Thank you in advance for your help!!
SCREENSHOTS BELOW
Here are the disks
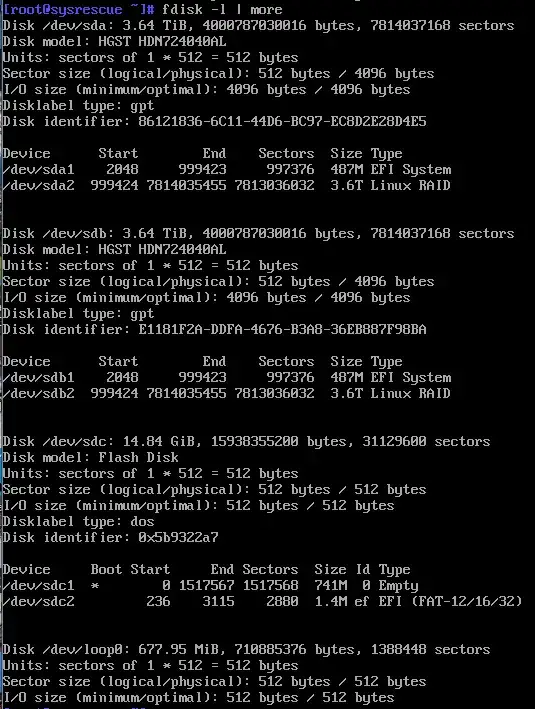 ]1
]1Superblock backups appear to exists
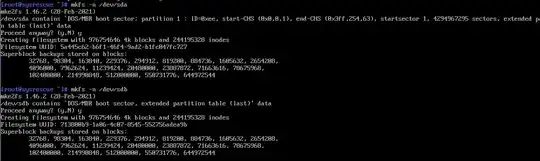
Drive and Filesystem structure

Can't use a backup superblock, bad magic number
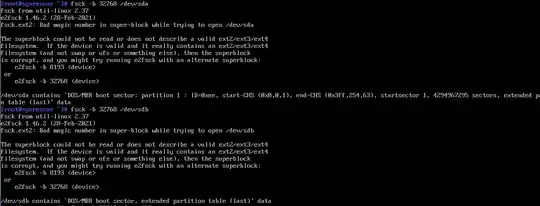
Can't force assembly either
{kind=link}