Searching for entries in a keyword-field stored in an Azure Cognitive Search index not returning expected results when searching for them in a long text. Multi word tokens as 'microsoft azure' are not returned as a match when looking in the text "This text contains microsoft azure"
Working with Azure Cognitive Search with the Python SDK. Say I'm building a search index where each document in the index has a "name" field. The name field (which can consist of multiple words) only makes sense if I tokenize the entire name is one token, so I use the "keyword_v2" tokenizer when building the analyzer for this field.
from azure.search.documents.indexes.models import CustomAnalyzer
# Define the custom analyzer for the Name field
name_analyzer = CustomAnalyzer(name="name_analyzer",tokenizer_name="keyword_v2",
token_filters=["lowercase"])`
# Specify the index schema
fields = [
SimpleField(name="key", type=SearchFieldDataType.String, key=True),
SearchableField(name="name", type=SearchFieldDataType.String, analyzer_name="name_analyzer", searchable=True)
]
This works as expected when I test the analyzer using the REST API. As an example I have the following indexed entries in the name-field: ['microsoft azure', 'amazon aws', 'google cloud']. The custom analyzer I set up correctly tokenizes each entry as one token and not as multiple tokens (ex. 'microsoft' and 'azure').
The problem occurs when I search for the stored names in a text.
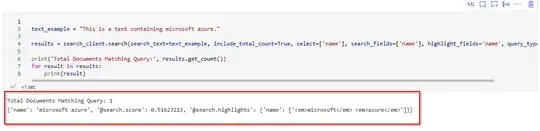
text_example = "This is a text containing microsoft azure."
results = search_client.search(search_text=text_example, include_total_count=True, select= ['name'], search_fields= ['name'], highlight_fields= 'name', query_type= "full")
print ('Total Documents Matching Query:', results.get_count())
for result in results:
print(result)
I expect when I search for a name in the text_example it will return a hit on 'microsoft azure', but it doesn't. It returns empty. I suspect because I use the same custom analyzer as both the index analyzer and search analyzer, it will tokenize the entire text_example as one token, which is not in the index. So it returns nothing.
Can I resolve this problem of searching for multiple word tokens in a long text in an efficient way using Azure Cognitive Search ?
Basically, I want the equivalent of the following Python snippet but with Azure Cognitive Search Index:
name_list = ['microsoft azure', 'amazon aws', 'google cloud']
text_example = "This is a text containing microsoft azure."
for name in name_list:
if name in text_example:
print(f"Match found: {name}) #Ideally it would return the field you are looking for and just the matched term.