Note I am not an expert on the subject, and this answer likely contains factual errors. Posting this hoping that someone will correct me as I am also interested in the matter.
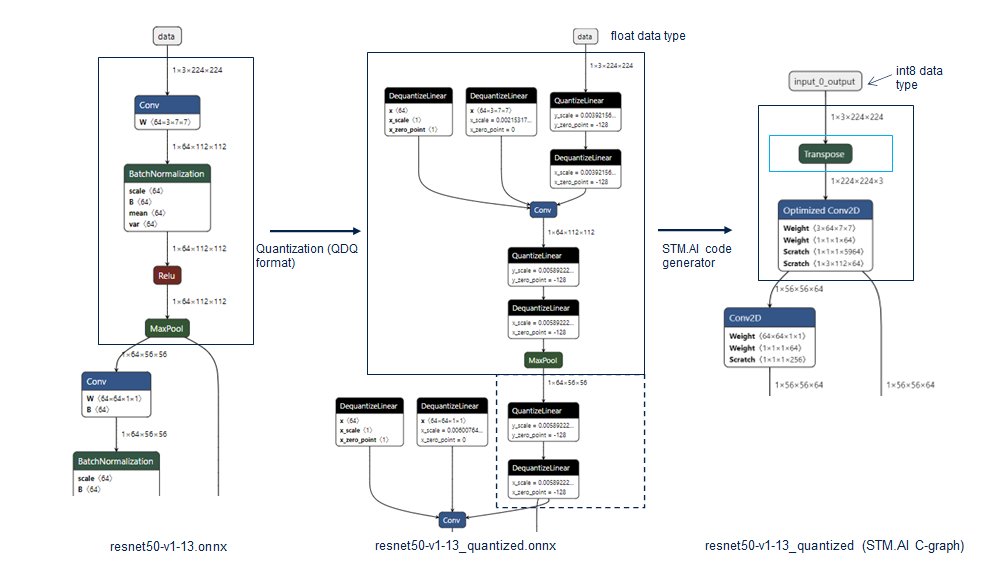
If you exported a torch model to ONNX with their quantization tools, the resulting model is likely in QDQ format. What this means, as far as I have understood it, is that in the exported graph there is a quantization and a dequantization layer inserted before every Operator. Then when onnxruntime parses and optimizes the model, these structures are detected and replaced with the correct integer Operators.
An illustration, leftmost graph is the original model, center is the exported ONNX model, and on the right what onnxruntime actually executes after optimizing the graph. So during the creation of an InferenceSession, intermediate tensors are promoted to INT32 or FP32, hence the high memory use.
My suggestion would be to try Operator-oriented quantization, where instead of the fake QDQ layers, the ONNX model has the correct integer Operators in the graph definition before any optimizations. ORT provides tools for both quantization formats. Albeit I have no idea how all of this works with your 2-bit packing scheme.
Another thing worth trying is to play around with SessionOptions.graph_optimization_level. Graph optimization during initalization can consume a lot of memory, disabling or toning it down could potentially help a bit.
{kind=link}