I am working with the current tidytuesday data about salaries and trying to create a model with tidymodels and recipes. I want to predict salary with many of the other factors present using the recipes code, but I run into an issue.
Issue 1 - My recipe says there are empty rows, but I do not know how to figure out how. This does not give an error, so maybe it is not a problem.
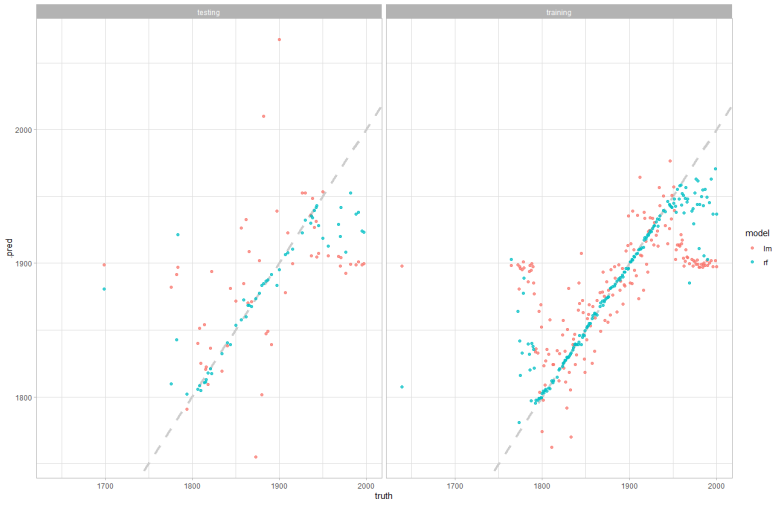
Issue 2 - Understanding what my models actually did and how to visualize the performance. I want to plot the models performance on the initial data. Here is an example of my goal: https://indescribled.files.wordpress.com/2021/05/image-17.png?w=782
I do not understand exactly how to use the predict function with my recipe. juice(rec) is less than 1000 rows while the testing data is about 6000. Perhaps I am reading it backwards, but can someone try to point me in the right direction?
The code below should be an exact reproduction of mine.
library(tidymodels)
library(tidyverse)
salary_raw <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2021/2021-05-18/survey.csv')
# Could not figure out tidy way to do this
salary_raw$other_monetary_comp[is.na(salary_raw$other_monetary_comp)] <- 0
salary_raw$other_monetary_comp <- as.numeric(salary_raw$other_monetary_comp)
# Filter and convert to USD
# The mutations to industry were because of other errors, they may not be needed
salary_modeling <- salary_raw %>%
filter(
how_old_are_you %in% c("55-64","45-54","35-44","25-34","18-24"),
currency %in% c("AUD/NZD","CAD","EUR","GBP","USD")
) %>%
mutate(annual_salary = case_when(
currency == "USD" ~ annual_salary * 1.00,
currency == "GBP" ~ annual_salary * 1.42,
currency == "AUD/NZD" ~ annual_salary * 0.75,
currency == "CAD" ~ annual_salary * 0.83,
currency == "EUR" ~ annual_salary * 1.22
)) %>%
mutate(other_monetary_comp = case_when(
currency == "USD" ~ other_monetary_comp * 1.00,
currency == "GBP" ~ other_monetary_comp * 1.42,
currency == "AUD/NZD" ~ other_monetary_comp * 0.75,
currency == "CAD" ~ other_monetary_comp * 0.83,
currency == "EUR" ~ other_monetary_comp * 1.22
)) %>%
rename(age = how_old_are_you,
prof_exp = overall_years_of_professional_experience,
field_exp = years_of_experience_in_field,
education = highest_level_of_education_completed
) %>%
mutate(total_comp = annual_salary + other_monetary_comp) %>%
filter(total_comp > 10000,
total_comp < 350000)%>%
mutate(gender = case_when(
gender == "Prefer not to answer" ~ "Other or prefer not to answer",
TRUE ~ gender
)) %>%
mutate(industry = case_when(
industry == "Biotech pharmaceuticals" ~ "Biotech",
industry == "Consumer Packaged Goods" ~ "Consumer packaged goods ",
industry == "Real Estate Development" ~ "Real Estate",
TRUE ~ industry
))
# Create initial splits
set.seed(123)
salary_split <- initial_split(salary_modeling)
salary_train <- training(salary_split)
salary_test <- testing(salary_split)
# I want to predict total comp with many of the other variables, listed below. Here is my logic
# downsample is because there are a lot more women than men in the data, unsure if necessary
# log is to many data more interpretable, not necessary
# an error message told me to use novel
# unknown is to change NA to unknown as far as I understand
# other is to change values that are less than 5% of the total dataset to "Other"
# unsure what the purpose of dummy is, but it seems to be necessary for modeling
rec <- salary_train %>%
recipe(total_comp ~ age + gender + field_exp + race + industry + job_title) %>%
themis::step_downsample(gender) %>%
step_log(total_comp, base = 2) %>%
step_novel(race, industry) %>%
step_unknown(race, industry, gender) %>%
step_other(race, industry, job_title, threshold = .005) %>%
step_dummy(all_nominal(), -all_outcomes()) %>%
prep()
# ISSUE 1 - Running rec says that there are 19,081 data points and 226 incomplete rows. I do not know how to fix the incomplete rows
test_proc <- bake(rec, new_data = salary_test)
# Linear model ------------------------------------------------------------
lm_spec <- linear_reg() %>%
set_engine("lm")
lm_fitted <- lm_spec %>%
fit(total_comp ~ ., data = juice(rec))
tidy(lm_fitted)
# RF MODEL ----------------------------------------------------------------
rf_spec <- rand_forest(mode = "regression", trees = 1500) %>%
set_engine("ranger")
rf_fit <- rf_spec %>%
fit(total_comp ~ .,
data = juice(rec))
rf_fit
# QUESTIONS BEGIN HERE --------------------------------------------------------------------------------------------------------------------------------------------------
# Need to figure out what new data is for this portion
# I think it is juice(rec), but it seems weird to me
# juice(rec) is only about 900 rows while test_proc is multiple thousand. testing data should be smaller than training
asdf <- juice(rec)
results_train <- lm_fitted %>%
predict(new_data = asdf) %>%
mutate(
truth = asdf$total_comp,
model = "lm"
) %>%
bind_rows(rf_fit %>%
predict(new_data = asdf) %>%
mutate(
truth = asdf$total_comp,
model = "rf"
))
results_train
# Is the newdata and test proc correct?
results_test <- lm_fitted %>%
predict(new_data = test_proc) %>%
mutate(
truth = test_proc$total_comp,
model = "lm"
) %>%
bind_rows(rf_fit %>%
predict(new_data = test_proc) %>%
mutate(
truth = test_proc$total_comp,
model = "rf"
))
results_test
# Goal is to run the following code to visualize the predictions, the code below probably will do nothing right now unless the two dataframes above are correct
results_test %>%
mutate(train = "testing") %>%
bind_rows(results_train %>%
mutate(train = "training")) %>%
ggplot(aes(truth, .pred, color = model)) +
geom_abline(lty = 2, color = "gray80", size = 1.5) +
geom_point(alpha = .75) +
facet_wrap(~train)

{kind=link}